
What is the difference between data scraping and data crawling
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
What is a crawler in data engineering
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
What is Spidering data
Web search engines and some other websites use Web crawling or spidering software to update their web content or indices of other sites' web content. Web crawlers copy pages for processing by a search engine, which indexes the downloaded pages so that users can search more efficiently.
How to crawl data from website using Python
To extract data using web scraping with python, you need to follow these basic steps:Find the URL that you want to scrape.Inspecting the Page.Find the data you want to extract.Write the code.Run the code and extract the data.Store the data in the required format.
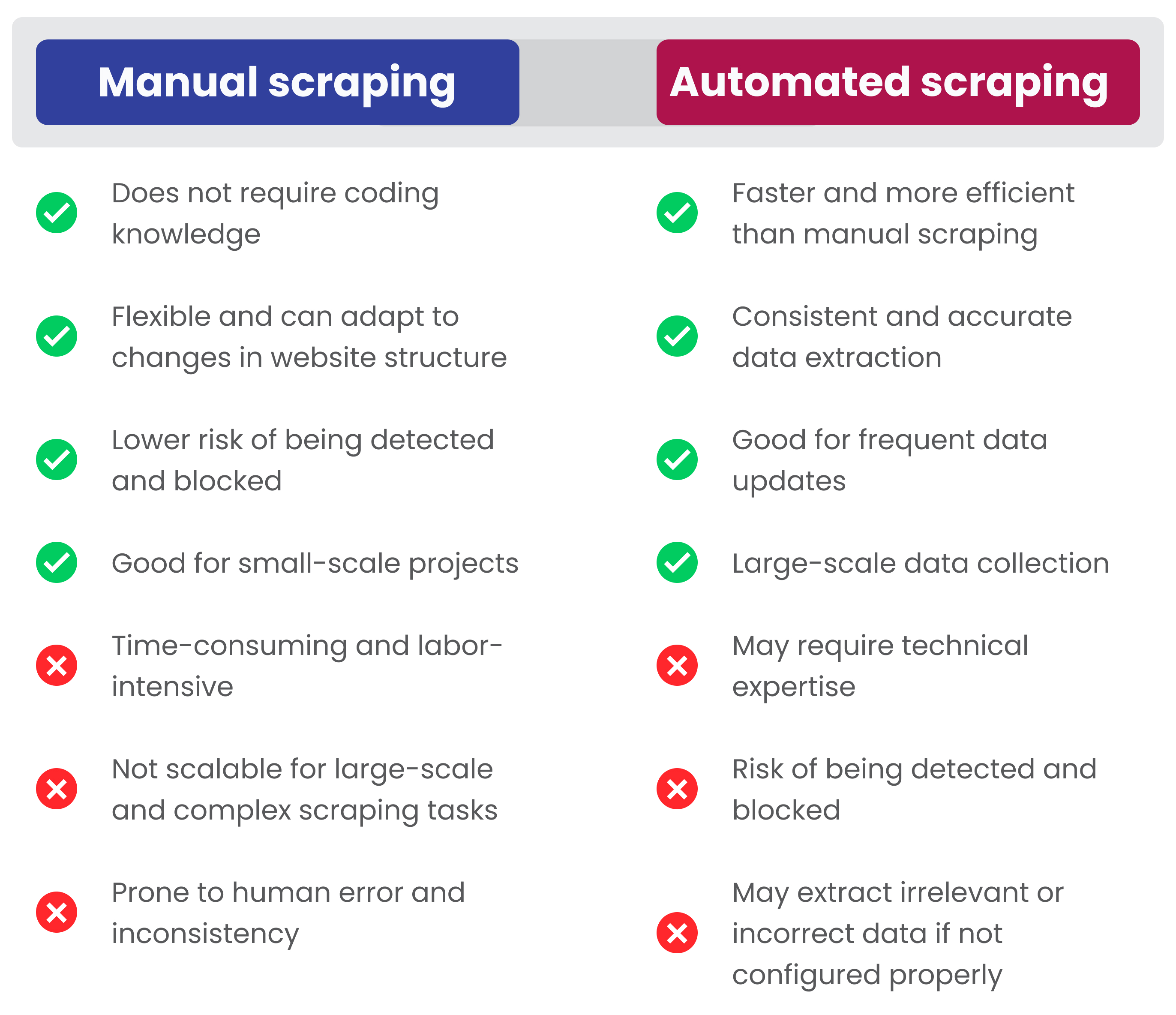
What is manual data scraping
The simplest form of web scraping is manually copying and pasting data from a web page into a text file or spreadsheet.
How to do data crawling
Here are the basic steps to build a crawler:Step 1: Add one or several URLs to be visited.Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread.Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
What is the difference between crawler and robot
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
What is the difference between crawler and classifier
Classifier types include defining schemas based on grok patterns, XML tags, and JSON paths. If you change a classifier definition, any data that was previously crawled using the classifier is not reclassified. A crawler keeps track of previously crawled data.
How do you do data crawling
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
What is the difference between crawling and Spidering
Spider- A browser like program that downloads web pages. Crawler- A program that automatically follows all of the links on each web page.
How do I scrape data from a website without coding
ParseHub is a free cloud-based web scraping tool that makes it easy for users to extract online data from websites, whether static or dynamic. With its simple point-and-click interface, you can start selecting the data you want to extract without any coding required.
How do you crawl data from a website
There are roughly 5 steps as below:Inspect the website HTML that you want to crawl.Access URL of the website using code and download all the HTML contents on the page.Format the downloaded content into a readable format.Extract out useful information and save it into a structured format.
Can data scraping be automated
Once the machine is programmed to mimic a human user where required, automating the web scraping setup is a relatively simple process. A queuing system is used to stack up the URLs to be scraped and the crawler setup will visit these pages, one by one thereby extracting the data from them.
What is manual data process
1. Manual Data Processing. In manual data processing, data is processed manually without using any machine or tool to get required results. In manual data processing, all the calculations and logical operations are performed manually on the data. Similarly, data is transferred manually from one place to another.
Is data crawling ethical
Crawlers are involved in illegal activities as they make copies of copyrighted material without the owner's permission. Copyright infringement is one of the most important legal issues for search engines that need to be addressed upon.
What is crawling vs indexing
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages.
Why is CNC not a robot
Workspace — The workspace of a CNC machine can usually be defined as a small cube. Robots, by contrast, usually have a large, spherical workspace. Programming — CNC machines are programmed using G-Code. These days, this is most often generated by a CAM software, not coded by hand.
What is the difference between robot and Cobot
The main differences between robots and cobots
While a robot performs a task without human control, a cobot performs tasks in collaboration with human workers.
What is the difference between web scraping and crawler
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
Are there different types of crawling
Not every infant crawls in the traditional manner. Different crawling styles include: Classic hands-and-knees or cross crawl. This is when babies bear weight on their hands and knees, then moves one arm and the opposite knee forward at the same time.
What are the methods of web crawling
Web crawlers start their crawling process by downloading the website's robot. txt file (see Figure 2). The file includes sitemaps that list the URLs that the search engine can crawl. Once web crawlers start crawling a page, they discover new pages via hyperlinks.
How do I manually scrape a website
There are roughly 5 steps as below:Inspect the website HTML that you want to crawl.Access URL of the website using code and download all the HTML contents on the page.Format the downloaded content into a readable format.Extract out useful information and save it into a structured format.
Can you pull data from a website without an API
Use web scrapers
If you need data from a popular website such as Amazon or Twitter, which you may save time by using already available web scraper solutions instead of getting API access.
What is the difference between web scraping and web crawling
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
Do you use technology to scrape or will it be done manually
Although web scraping can be done manually, in most cases, automated tools are preferred when scraping web data as they can be less costly and work at a faster rate. But in most cases, web scraping is not a simple task.

