
Does Google use web crawling
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.
Does Google crawl JavaScript generated content
As Googlebot can crawl and render JavaScript content, there is no reason (such as preserving crawl budget) to block it from accessing any internal or external resources needed for rendering. Doing so would only prevent your content from being indexed correctly, and thus, poor SEO performance.
How often does Google crawl webpages
It's a common question in the SEO community and although crawl rates and index times can vary based on a number of different factors, the average crawl time can be anywhere from 3-days to 4-weeks. Google's algorithm is a program that uses over 200 factors to decide where websites rank amongst others in Search.
What is Google crawling
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Does Google use spiders or crawlers
Google uses crawlers and fetchers to perform actions for its products, either automatically or triggered by user request. "Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another.
Is Ajax bad for SEO
Single page web applications that use AJAX frameworks have historically been very problematic from an SEO standpoint and caused problems such as: Crawling issues: Important content was hidden behind unparsed JavaScript which only rendered on the client side, meaning Google would essentially just see a blank screen.
Do crawlers run JavaScript
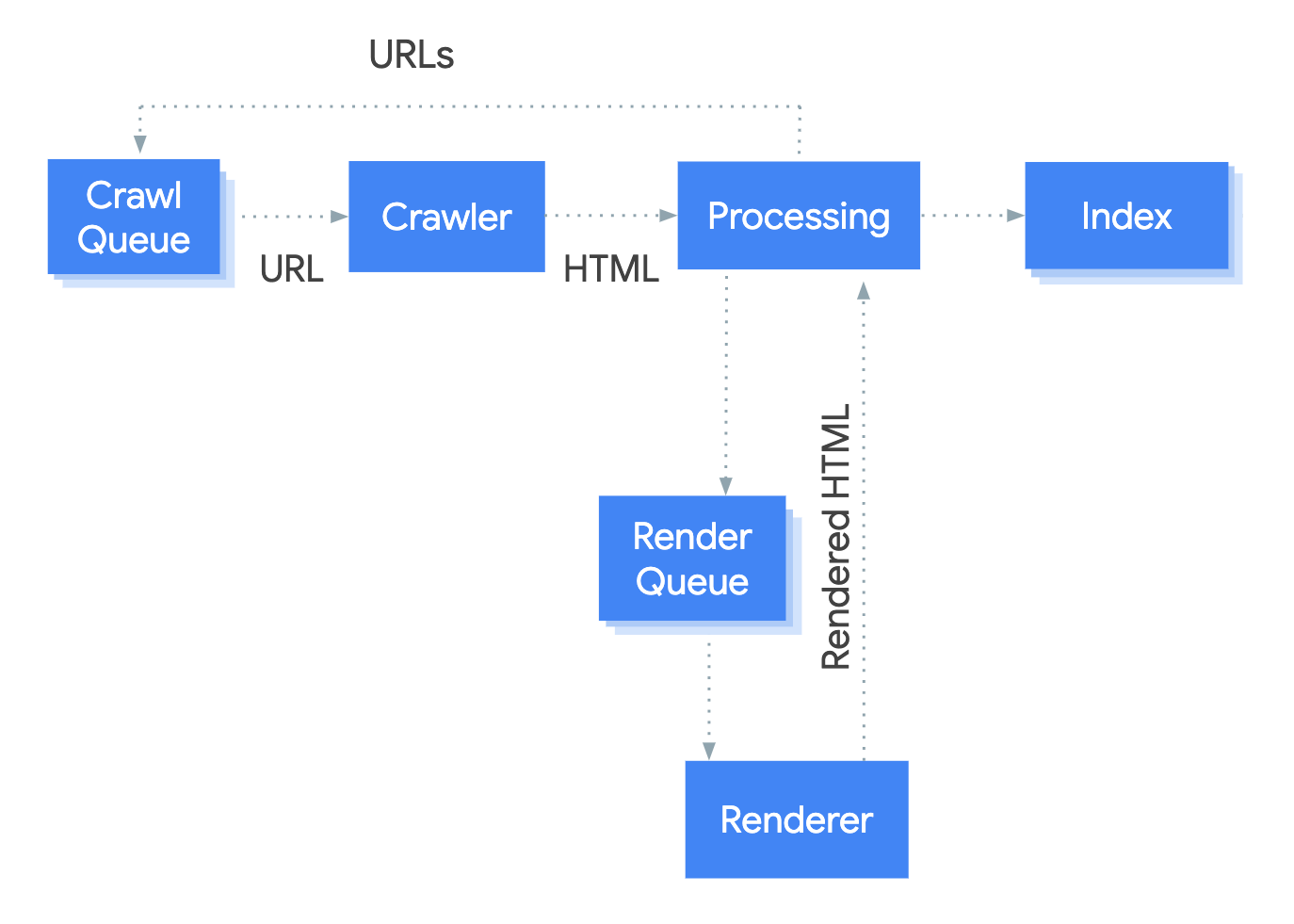
At the crawler stage, any new links (URLs) that Googlebot discovers are sent back to the crawl queue. The HTML content on the parsed page may then be indexed. Processing (rendering). At this point, the URL will be processed for JavaScript.
Why did Google stop crawling my site
Did you recently create the page or request indexing It can take time for Google to index your page; allow at least a week after submitting a sitemap or a submit to index request before assuming a problem. If your page or site change is recent, check back in a week to see if it is still missing.
How do I stop Google from crawling my website
Stay organized with collections Save and categorize content based on your preferences. noindex is a rule set with either a <meta> tag or HTTP response header and is used to prevent indexing content by search engines that support the noindex rule, such as Google.
What is an example website for crawling
Some examples of web crawlers used for search engine indexing include the following: Amazonbot is the Amazon web crawler. Bingbot is Microsoft's search engine crawler for Bing. DuckDuckBot is the crawler for the search engine DuckDuckGo.
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
Is web scraping YouTube legal
Most data on YouTube is publicly accessible. Scraping public data from YouTube is legal as long as your scraping activities do not harm the scraped website's operations. It is important not to collect personally identifiable information (PII), and make sure that collected data is stored securely.
How many crawlers does Google use
two types
Stay organized with collections Save and categorize content based on your preferences. Googlebot is the generic name for Google's two types of web crawlers: Googlebot Desktop: a desktop crawler that simulates a user on desktop. Googlebot Smartphone: a mobile crawler that simulates a user on a mobile device.
Is JavaScript bad for SEO
To simply answer is JavaScript bad for SEO: it's not bad, in fact when used and implemented correctly it can improve ranking and user experience by adding interactive interfaces, and help to retain visitors on your website for longer.
Do pop ups harm SEO
It's a full-screen pop-up that appears before a content page. Now, let's have a look at the top takes from these guidelines. First, websites using “intrusive interstitials” could be penalized. So yes, if you don't respect Google's guidelines, pop-ups can pose SEO risks.
Do bots trigger JavaScript
These days, it's easy for attackers to create bots that can execute JavaScript (JS). Open-source libraries like Puppeteer, Playwright, and Selenium are used to instrument headless browsers, and bots as a service spawn browsers in the cloud on behalf of their customers—all of which can execute JS.
Do bots use JavaScript
The web server sends the challenge to each client as JavaScript code embedded in a web page. Since most popular browsers have a JavaScript stack, they will be able to understand and pass the challenge transparently. In contrast, bots typically do not have a JavaScript stack and, therefore, cannot pass the challenge.
Is Google blocking my site
Visit the Google Transparency Report. Enter your website URL into the Check site status search field. Submit your search to view the report.
Why is Google blocking every website
Why sites are labeled or blocked. Google checks the pages that it indexes for malicious scripts or downloads, content violations, policy violations, and many other quality and legal issues that can affect users.
How do I stop HTML from indexing
If search engines have already indexed your content, you can add a "noindex" meta tag to the content's head HTML. This will tell search engines to stop displaying it in search results. Please note: only content hosted on a domain connected to HubSpot can be blocked in your robots.
Do websites block web crawlers
Web pages detect web crawlers and web scraping tools by checking their IP addresses, user agents, browser parameters, and general behavior. If the website finds it suspicious, you receive CAPTCHAs and then eventually your requests get blocked since your crawler is detected.
What is web crawling in HTML
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
Is it illegal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
Can websites detect scrapers
Web pages detect web crawlers and web scraping tools by checking their IP addresses, user agents, browser parameters, and general behavior. If the website finds it suspicious, you receive CAPTCHAs and then eventually your requests get blocked since your crawler is detected.

