
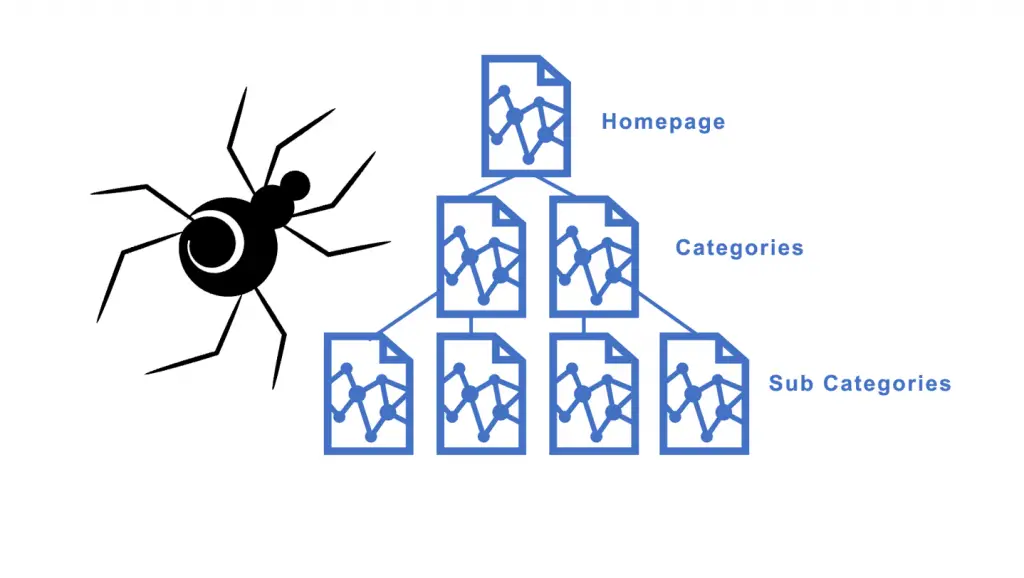
Does Google use spiders
Google uses crawlers and fetchers to perform actions for its products, either automatically or triggered by user request. "Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another.
Does Google use web crawler
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.
How many crawlers does Google use
two types
Stay organized with collections Save and categorize content based on your preferences. Googlebot is the generic name for Google's two types of web crawlers: Googlebot Desktop: a desktop crawler that simulates a user on desktop. Googlebot Smartphone: a mobile crawler that simulates a user on a mobile device.
Are web crawlers and spiders the same
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering).
Do search engines use spiders
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
What is Google crawling
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Does Google crawl HTML
Google can only crawl your link if it's an <a> HTML element with an href attribute.
How many NASA crawlers are there
two crawlers
Kennedy Space Center has been using the same two crawlers since their initial delivery in 1965. They are now nicknamed "Hans and Franz", after the parodic Austrian body-builder characters on Saturday Night Live, played by Dana Carvey and Kevin Nealon.
How many spiders Google use at a time
Google uses multiple spiders, three at a time.
Are web crawlers illegal
United States: There are no federal laws against web scraping in the United States as long as the scraped data is publicly available and the scraping activity does not harm the website being scraped.
How do Google spiders work
A search engine spider, also known as a web crawler, is an Internet bot that crawls websites and stores information for the search engine to index. Think of it this way. When you search something on Google, those pages and pages of results can't just materialize out of thin air.
Do search engines use crawlers
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
Do all search engines use web crawlers
Most popular search engines have their own web crawlers that use a specific algorithm to gather information about webpages. Web crawler tools can be desktop- or cloud-based. Some examples of web crawlers used for search engine indexing include the following: Amazonbot is the Amazon web crawler.
How do I force Google to crawl
Here's Google's quick two-step process:Inspect the page URL. Enter in your URL under the “URL Prefix” portion of the inspect tool.Request reindexing. After the URL has been tested for indexing errors, it gets added to Google's indexing queue.
Does Google crawl images
Google will still crawl your page and see the image, but will display a thumbnail image generated at crawl time in search results. This opt-out is possible at any time, and doesn't require re-processing of a website's images. This behavior isn't considered image cloaking and won't result in manual actions.
Is scraping TikTok legal
Scraping publicly available data on the web, including TikTok, is legal as long as it complies with applicable laws and regulations, such as data protection and privacy laws.
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
How does Google crawl
Crawling: Google searches the web with automated programs called crawlers, looking for pages that are new or updated. Google stores those page addresses (or page URLs) in a big list to look at later. We find pages by many different methods, but the main method is following links from pages that we already know about.
Can Google crawl CSS
“Googlebot can crawl the first 15MB of an HTML file or supported text-based file. Any resources referenced in the HTML such as images, videos, CSS, and JavaScript are fetched separately.
Does NASA still use the crawlers
NASA currently plans to use crawler-transporter 2 to transport the Space Launch System with the Orion spacecraft atop it from the Vehicle Assembly Building to Launch Pad 39B for the Artemis missions.
How fast is NASA crawler
The crawler is the size of a baseball infield. The crawler's top speed is one mile per hour loaded and two miles per hour unloaded.
How often does Google spider crawl
For sites that are constantly adding and updating content, the Google spiders will crawl more often—sometimes multiple times a minute! However, for a small site that is rarely updated, the Google bots will only crawl every few days.
Is web scraping YouTube legal
Most data on YouTube is publicly accessible. Scraping public data from YouTube is legal as long as your scraping activities do not harm the scraped website's operations. It is important not to collect personally identifiable information (PII), and make sure that collected data is stored securely.
Is Yahoo a crawler search engine
Yahoo provides effective web search features to users. It uses powerful algorithm and crawlers that helps it to list the webpages related to user query and keywords.

