
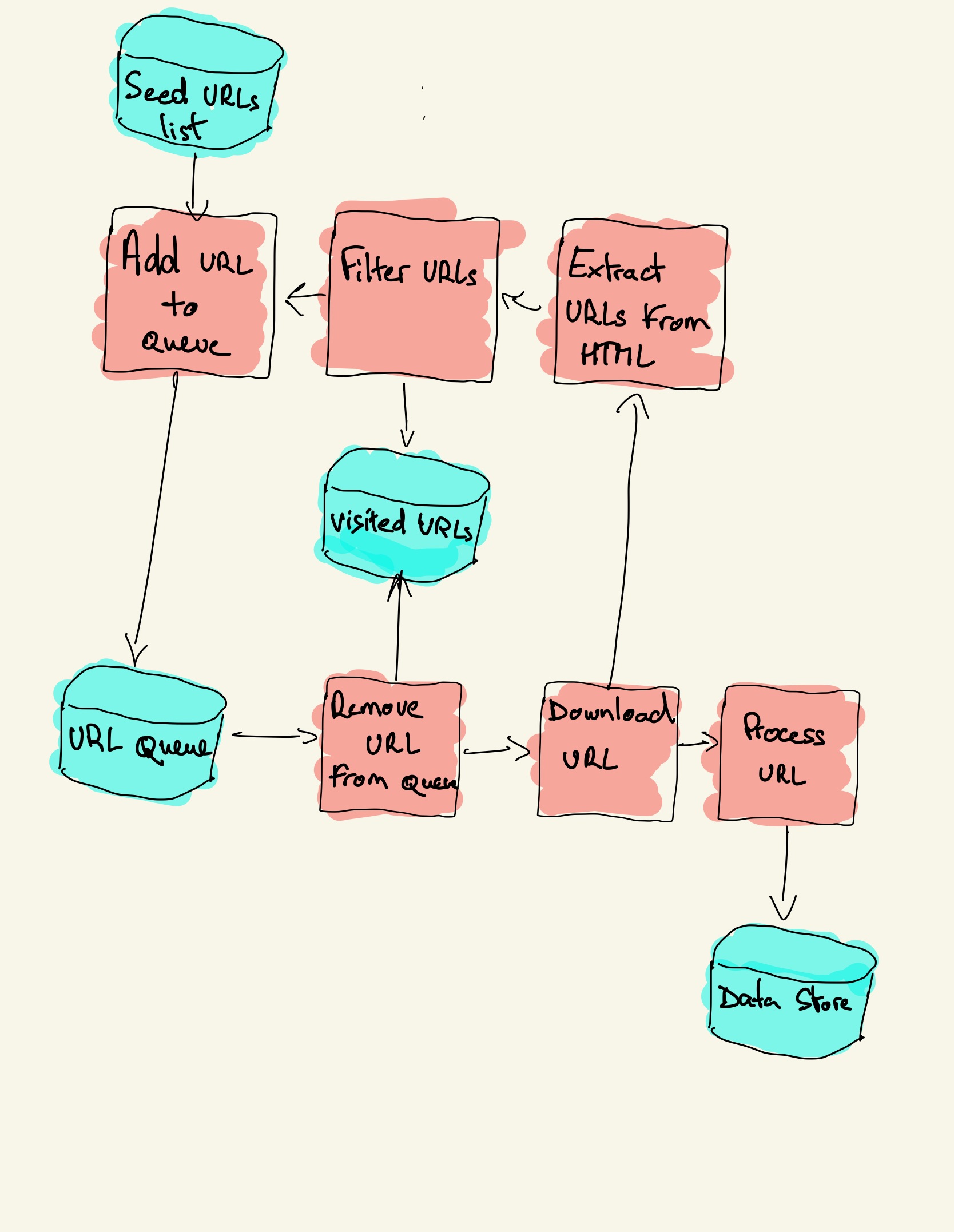
Can a web crawler collect all pages on the web
Because it is not possible to know how many total webpages there are on the Internet, web crawler bots start from a seed, or a list of known URLs. They crawl the webpages at those URLs first. As they crawl those webpages, they will find hyperlinks to other URLs, and they add those to the list of pages to crawl next.
How to implement web crawler in Python
Building a Web Crawler using Pythona name for identifying the spider or the crawler, “Wikipedia” in the above example.a start_urls variable containing a list of URLs to begin crawling from.a parse() method which will be used to process the webpage to extract the relevant and necessary content.
What is the difference between scrapy and crawl
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
What is Python crawler
Basic workflow of web crawlers
Get the initial URL. The initial URL is an entry point for the web crawler, which links to the web page that needs to be crawled; While crawling the web page, we need to fetch the HTML content of the page, then parse it to get the URLs of all the pages linked to this page.
How do I crawl an entire website
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
How do I crawl all URLs from a website
How to extract all URLs from a webpageStep 1: Run JavaScript code in Google Chrome Developer Tools. Open Google Chrome Developer Tools with Cmd + Opt + i (Mac) or F12 (Windows).Step 2: Copy-paste exported URLs into a CSV file or spreadsheet tools.Step 3: Filter CSV data to get relevant links.
How do I crawl multiple websites in Python
The method goes as follows:Create a “for” loop scraping all the href attributes (and so the URLs) for all the pages we want.Clean the data and create a list containing all the URLs collected.Create a new loop that goes over the list of URLs to scrape all the information needed.
How do you crawl data from a website in Python
To extract data using web scraping with python, you need to follow these basic steps:Find the URL that you want to scrape.Inspecting the Page.Find the data you want to extract.Write the code.Run the code and extract the data.Store the data in the required format.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Is Scrapy better than BeautifulSoup
Generally, we recommend sticking with BeautifulSoup for smaller or domain-specific scrapers and using Scrapy for medium to big web scraping projects that need more speed and control over the whole scraping process.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How do I pull all content from a website
There are several ways of manual web scraping.Code a web scraper with Python. It is possible to quickly build software with any general-purpose programming language like Java, JavaScript, PHP, C, C#, and so on.Use a data service.Use Excel for data extraction.Web scraping tools.
How do I get a list of all pages on a website
Look it up with Google search operators
Google search can quickly help find all the pages of a website. Simply enter the "site: your domain" into the search bar, and Google will show you all the pages of the website that it has indexed.
Is scraping TikTok legal
Scraping publicly available data on the web, including TikTok, is legal as long as it complies with applicable laws and regulations, such as data protection and privacy laws.
Can you get sued for scraping data
Additional Common Law Claims
In addition to breach of contract claims, website hosts often sue those engaged in scraping for common law claims of trespass to chattels and unjust enrichment .
Is web scraping easier in Python or R
Junior developers who require basic web scraping, data processing, and scalability prefer Python. Is R easier than Python Both R and Python programming languages are easy to learn. However, Python has a better learning curve due to syntactic sugar, i.e., simple keyword-based syntax.
Is Selenium faster than BeautifulSoup
The main advantages of BeautifulSoup over Selenium are: It's faster. It's beginner-friendly and easier to set up. It works independently from browsers.
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
How do I scrape data from multiple pages on a website
How to Scrape Multiple Web Pages Using PythonSeek permission before you scrape a site.Read and understand the website's terms of service and robots. txt file.Limit the frequency of your scraping.Use web scraping tools that respect website owners' terms of service.
Is it legal to scrape RSS feed
RSS scrapers grab content from any website and use it for their own search engine gains. This type of spam is among the most detested in the Internet. Illegal RSS feed scrapers can be a real problem for webmasters and bloggers so it is essential to ensure that your content is protected.
Is there a way to print all pages of a website
Click the “Pages” drop-down menu, and then select your desired option. #* To print everything on the page you have open, select All pages. To print only the page that appears in the preview on the right side of the window, select Current page.
Is there a way to find out how many pages a website has
Using the Google Search Console
On the Index Status page, you will be able to see the number of indexed pages. This number will include many different types of pages which could be confusing to anyone who isn't fully aware of the makeup of a website.
Can I get in trouble for web scraping
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
Can you be banned from scraping
If your scraper makes too many requests from an IP address, websites can block that IP. In that case, you can use a proxy server with a different IP. It'll act as an intermediary between your web scraping script and the website host.
Is it illegal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.

