
Is My website Crawlable
There are several factors that affect crawlability, including the structure of your website, internal link structure, and the presence of robots. txt files. In order to ensure that your website is crawlable, you need to make sure that these factors are taken into account.
Why is my website not crawling
Over time, Google will stop crawling the links on those pages altogether. So, if your pages are not getting crawled, long-term “noindex” tags could be the culprit. Identify pages with a “noindex” tag using Semrush's Site Audit tool. Set up a project in the tool and run your first crawl.
How do I crawl my website
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
How do I identify a web crawler
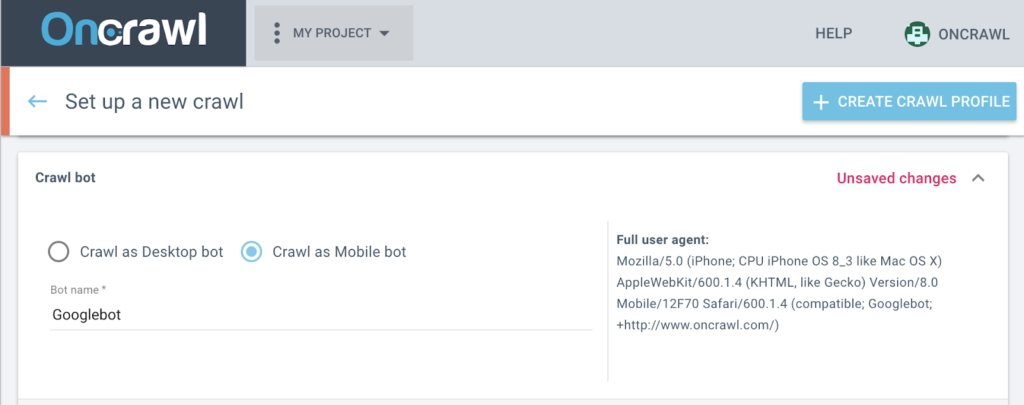
Crawler identification
Web crawlers typically identify themselves to a Web server by using the User-agent field of an HTTP request. Web site administrators typically examine their Web servers' log and use the user agent field to determine which crawlers have visited the web server and how often.
How do I crawl my own website
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
Can I crawl any website
As long as you are not crawling at a disruptive rate and the source is public you should be fine. I suggest you check the websites you plan to crawl for any Terms of Service clauses related to scraping of their intellectual property. If it says “no scraping or crawling”, maybe you should respect that.
How do I submit my website to Google crawler
Submit a Page URL to Google
This is pretty simple too. In Search Console, go to URL inspection and paste in your page URL you want to index. If you've recently updated content and want Google to recrawl the page, you can click on 'Request Indexing' to index those page changes.
How do I crawl all URLs from a website
How to extract all URLs from a webpageStep 1: Run JavaScript code in Google Chrome Developer Tools. Open Google Chrome Developer Tools with Cmd + Opt + i (Mac) or F12 (Windows).Step 2: Copy-paste exported URLs into a CSV file or spreadsheet tools.Step 3: Filter CSV data to get relevant links.
What are the methods of web crawling
Web crawlers start their crawling process by downloading the website's robot. txt file (see Figure 2). The file includes sitemaps that list the URLs that the search engine can crawl. Once web crawlers start crawling a page, they discover new pages via hyperlinks.
What is an example of web crawling
1. GoogleBot. As the world's largest search engine, Google relies on web crawlers to index the billions of pages on the Internet. Googlebot is the web crawler Google uses to do just that.
Does Google crawl every website
Google's crawlers are also programmed such that they try not to crawl the site too fast to avoid overloading it. This mechanism is based on the responses of the site (for example, HTTP 500 errors mean "slow down") and settings in Search Console. However, Googlebot doesn't crawl all the pages it discovered.
How do you check if I can scrape a website
There are websites, which allow scraping and there are some that don't. In order to check whether the website supports web scraping, you should append “/robots. txt” to the end of the URL of the website you are targeting. In such a case, you have to check on that special site dedicated to web scraping.
How do I crawl a website fast
A couple of simple tips to increase your site's crawl speed:Using the methods above, find and fix all the errors.Make sure your site is fast.Add an XML sitemap to your site and submit it to the search engines.If all of that fails to improve your crawl speed, start link building!
What is crawling in SEO
What Is Crawling In SEO. In the context of SEO, crawling is the process in which search engine bots (also known as web crawlers or spiders) systematically discover content on a website. This may be text, images, videos, or other file types that are accessible to bots.
How are websites crawled
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
How do I get my website crawled by Google
Here are the main ways to help Google find your pages:Submit a sitemap.Make sure that people know about your site.Provide comprehensive link navigation within your site.Submit an indexing request for your homepage.Sites that use URL parameters rather than URL paths or page names can be harder to crawl.
How do I get Google to crawl my website daily
How do I get Google to recrawl my websiteGoogle's recrawling process in a nutshell.Request indexing through Google Search Console.Add a sitemap to Google Search Console.Add relevant internal links.Gain backlinks to updated content.
Can you prevent your website from being scraped
There is no technical way to prevent web scraping
Let's review in detail how a website can withstand data grabbing attempts. Every web request contains a browser signature, so-called User agent, and in theory, a web server can detect and reject non-human browser requests.
Can a website stop you from scraping
Many websites use ReCaptcha from Google which lets you pass a test. If the test goes successful within a certain time frame then it considers that you are not a bot but a real human being. f you are scraping a website on a large scale, the website will eventually block you.
How to get 1,000 visitors per day on website
How To Get 1000 Visitors To Your New Blog Every DayStep 1) Create Great Content For Your Blog.Brainstorm and research high traffic keywords.Write a headline to sell people on your article.Create a top list article around keywords.Make Sure Your Blog Post Looks Amazing.Step 2) Search Engine Optimization.
How do I crawl a website without being blocked
13 Tips on How to Crawl a Website Without Getting BlockedHere are the main tips on how to crawl a website without getting blocked:Use a proxy server.Rotate IP addresses.Use real user agents.Set your fingerprint right.Beware of honeypot traps.Use CAPTCHA solving services.Change the crawling pattern.
How is a website crawled
Web crawlers work by starting at a seed, or list of known URLs, reviewing and then categorizing the webpages. Before each page is reviewed, the web crawler looks at the webpage's robots. txt file, which specifies the rules for bots that access the website.
How does Google crawl a site
We use a huge set of computers to crawl billions of pages on the web. The program that does the fetching is called Googlebot (also known as a crawler, robot, bot, or spider). Googlebot uses an algorithmic process to determine which sites to crawl, how often, and how many pages to fetch from each site.
Can we crawl any website
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Can Google crawl a site
Once Google discovers a page's URL, it may visit (or "crawl") the page to find out what's on it. We use a huge set of computers to crawl billions of pages on the web. The program that does the fetching is called Googlebot (also known as a crawler, robot, bot, or spider).

