
How to crawl data from website using Python
To extract data using web scraping with python, you need to follow these basic steps:Find the URL that you want to scrape.Inspecting the Page.Find the data you want to extract.Write the code.Run the code and extract the data.Store the data in the required format.
What is Python crawler
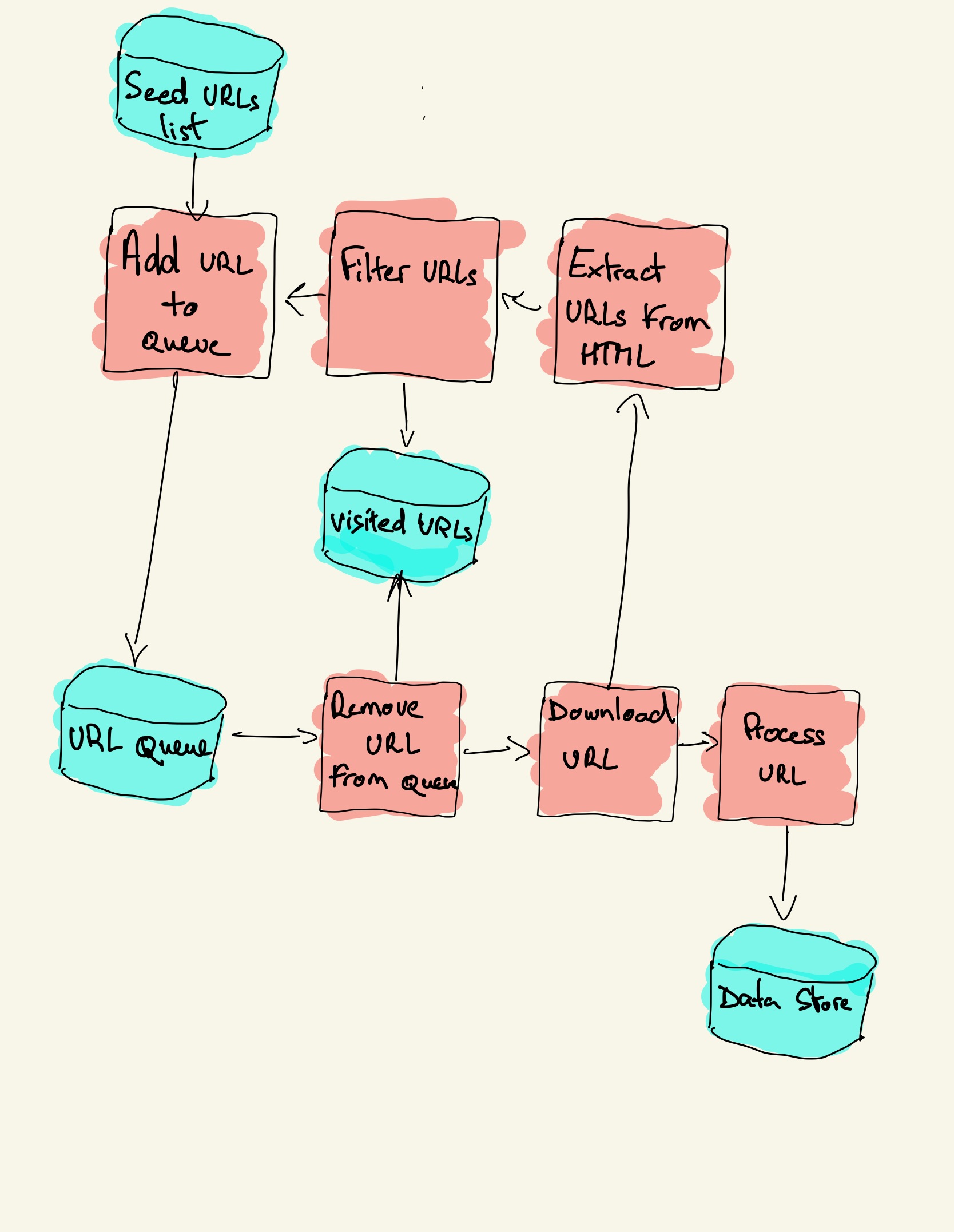
Basic workflow of web crawlers
Get the initial URL. The initial URL is an entry point for the web crawler, which links to the web page that needs to be crawled; While crawling the web page, we need to fetch the HTML content of the page, then parse it to get the URLs of all the pages linked to this page.
What is the difference between scrapy and crawl
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
What is an example of a web crawler
Some examples of web crawlers used for search engine indexing include the following: Amazonbot is the Amazon web crawler. Bingbot is Microsoft's search engine crawler for Bing. DuckDuckBot is the crawler for the search engine DuckDuckGo.
How do you crawl data from a website
There are roughly 5 steps as below:Inspect the website HTML that you want to crawl.Access URL of the website using code and download all the HTML contents on the page.Format the downloaded content into a readable format.Extract out useful information and save it into a structured format.
Can Python pull data from a website
Web scraping is the process of collecting and parsing raw data from the Web, and the Python community has come up with some pretty powerful web scraping tools. The Internet hosts perhaps the greatest source of information on the planet.
Can Python be used for web crawler
Web crawling is a powerful technique to collect data from the web by finding all the URLs for one or multiple domains. Python has several popular web crawling libraries and frameworks.
Why Scrapy is better than selenium
In a nutshell, Scrapy is best when dealing with large projects where efficiency and speed are top priorities. Selenium excels in dealing with core javascript based web applications, but it's good for projects where speed isn't relevant.
How do you make a crawler in Python
Building a Web Crawler using Pythona name for identifying the spider or the crawler, “Wikipedia” in the above example.a start_urls variable containing a list of URLs to begin crawling from.a parse() method which will be used to process the webpage to extract the relevant and necessary content.
How do you crawl a website
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
How do you write a crawler in Python
Make a web crawler using Python ScrapySetting up Scrapy. Open your cmd prompt. Run the command:Fetching the website. Use the fetch command to get the target webpage as a response object.Extracting Data from the website. Right-click the first product title on the page and select inspect element.
Is it illegal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
How do I extract data from a website
There are roughly 5 steps as below:Inspect the website HTML that you want to crawl.Access URL of the website using code and download all the HTML contents on the page.Format the downloaded content into a readable format.Extract out useful information and save it into a structured format.
How to get data from website using API in Python
Steps to pull data from an API using PythonConnect to an API. At first, we need to connect to an API and make a secure connection as shown below–Get the data from API.Parse the data into JSON format.Extract the data and print it.
How to make a crawler in Python
Building a Web Crawler using Pythona name for identifying the spider or the crawler, “Wikipedia” in the above example.a start_urls variable containing a list of URLs to begin crawling from.a parse() method which will be used to process the webpage to extract the relevant and necessary content.
Can Scrapy replace Selenium
To scrape data from a website that uses Javascript, Selenium is a better approach. However, you can use Scrapy to scrape JavaScript-based websites through the Splash library.
Is Scrapy better than BeautifulSoup
Generally, we recommend sticking with BeautifulSoup for smaller or domain-specific scrapers and using Scrapy for medium to big web scraping projects that need more speed and control over the whole scraping process.
Can Python be applied in web crawler
Develop web crawlers with Scrapy, a powerful framework for extracting, processing, and storing web data. If you would like an overview of web scraping in Python, take DataCamp's Web Scraping with Python course.
How do I crawl all URLs from a website
How to extract all URLs from a webpageStep 1: Run JavaScript code in Google Chrome Developer Tools. Open Google Chrome Developer Tools with Cmd + Opt + i (Mac) or F12 (Windows).Step 2: Copy-paste exported URLs into a CSV file or spreadsheet tools.Step 3: Filter CSV data to get relevant links.
How do I scrape all data from a website
There are roughly 5 steps as below:Inspect the website HTML that you want to crawl.Access URL of the website using code and download all the HTML contents on the page.Format the downloaded content into a readable format.Extract out useful information and save it into a structured format.
How do you crawl a website for information
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
How to extract data from a website using API
Now, we will use Acho as an example to demonstrate how to connect to your API with no coding.Configure the API endpoint. An API endpoint can be complex.Create an API resource.Store data into a database.Transform the API data.Export the data to an application.Check and maintain the pipeline.
Is it legal to extract data from a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
Should I use Selenium or Scrapy
If the data is included in html source code, both frameworks can work fine and you can choose one as you like. But in some cases the data show up after many ajax/pjax requests, the workflow make it hard to use Scrapy to extract the data. If you are faced with this situation, I recommend you to use Selenium instead.
Should I learn Selenium or Scrapy
The nature of work for which they're originally developed is different from one another. Selenium is an excellent automation tool and Scrapy is by far the most robust web scraping framework. When we consider web scraping, in terms of speed and efficiency Scrapy is a better choice.

