
What is crawling data
What is Data crawling Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
What is powerful web scraping and crawling with Python
Scrapy is a free and open source web crawling framework, written in Python. Scrapy is useful for web scraping and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
How to use Scrapy in Python
Use Scrapy for Web Scraping in PythonAn introduction to Scrapy and an overview of the course content.Setting up a virtual environment and installing Scrapy.Creating a new Scrapy project.Building your first Scrapy spider to crawl and extract data.
What is an example of a web crawler
Some examples of web crawlers used for search engine indexing include the following: Amazonbot is the Amazon web crawler. Bingbot is Microsoft's search engine crawler for Bing. DuckDuckBot is the crawler for the search engine DuckDuckGo.
How do you do data crawling
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
How do you make a crawler in Python
Building a Web Crawler using Python
The above class consists of the following components: a name for identifying the spider or the crawler, “Wikipedia” in the above example. a start_urls variable containing a list of URLs to begin crawling from. We are specifying a URL of a Wikipedia page on clustering algorithms.
How do you write a crawler in Python
Make a web crawler using Python ScrapySetting up Scrapy. Open your cmd prompt. Run the command:Fetching the website. Use the fetch command to get the target webpage as a response object.Extracting Data from the website. Right-click the first product title on the page and select inspect element.
How to use web crawler in Python
To build a simple web crawler in Python we need at least one library to download the HTML from a URL and another one to extract links. Python provides the standard libraries urllib for performing HTTP requests and html. parser for parsing HTML.
What is crawler in Python
They achieve this using a bot, called a web crawler. It surfs the internet, collects relevant links, and stores them. This is particularly useful in search engines and even web scraping. It is possible to code this web crawler on your own. All you need is to know some basic prerequisites of Python programming language.
How to code a data crawler
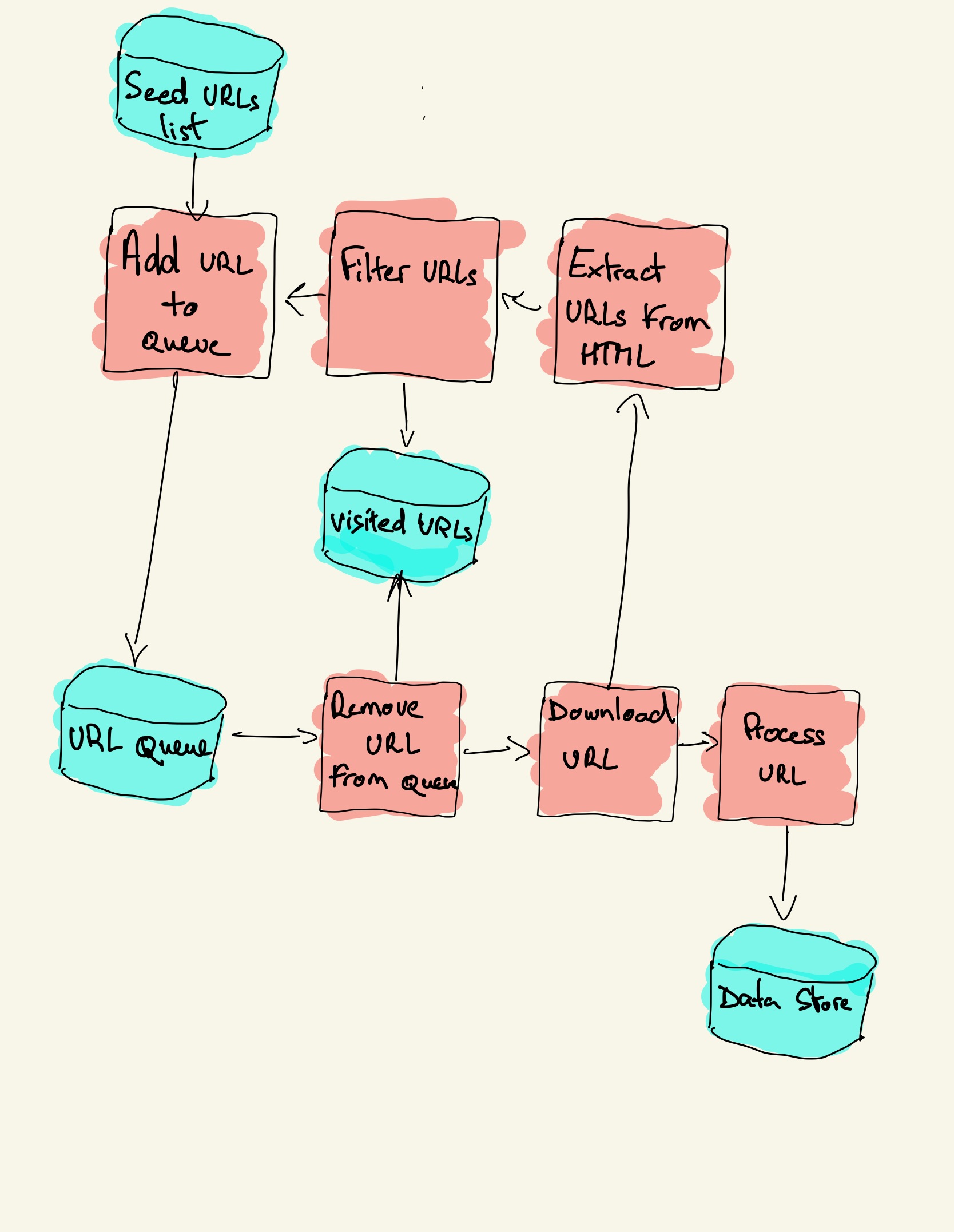
Here are the basic steps to build a crawler:Step 1: Add one or several URLs to be visited.Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread.Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How do you crawl data from a website
There are roughly 5 steps as below:Inspect the website HTML that you want to crawl.Access URL of the website using code and download all the HTML contents on the page.Format the downloaded content into a readable format.Extract out useful information and save it into a structured format.
How to make a crawler in Python
Building a Web Crawler using Pythona name for identifying the spider or the crawler, “Wikipedia” in the above example.a start_urls variable containing a list of URLs to begin crawling from.a parse() method which will be used to process the webpage to extract the relevant and necessary content.
How do data crawlers work
They crawl the webpages at those URLs first. As they crawl those webpages, they will find hyperlinks to other URLs, and they add those to the list of pages to crawl next. Given the vast number of webpages on the Internet that could be indexed for search, this process could go on almost indefinitely.
How to do data crawling
Here are the basic steps to build a crawler:Step 1: Add one or several URLs to be visited.Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread.Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
Is scraping TikTok legal
Scraping publicly available data on the web, including TikTok, is legal as long as it complies with applicable laws and regulations, such as data protection and privacy laws.
Can you be banned from scraping
If your scraper makes too many requests from an IP address, websites can block that IP. In that case, you can use a proxy server with a different IP. It'll act as an intermediary between your web scraping script and the website host.
Can I get in trouble for web scraping
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
Are scraping bots legal
United States: There are no federal laws against web scraping in the United States as long as the scraped data is publicly available and the scraping activity does not harm the website being scraped.
How long is a Scratch IP ban
In most cases, bans are temporary and the account is automatically unbanned after a set number of days, usually three, but if the ban is permanent (known as a "permaban"), that user has to contact the appropriate administration (the Scratch Team on the main website or a admin or bureaucrat on the wiki) in order to …
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
Can you sue a bot
Robots, in mimicking the work of humans, will also mimic their legal liability. But how do you sue a robot The current answer is that you cannot.
Does Roblox IP ban for a day
How long do IP bans last in Roblox This type of ban is reserved for very severe violations of the Terms of Service or federal law. All players on the banned accounts' IP Address are blocked for 7 days and will see a 403 error when trying to access the Roblox website.
Is Scratch banned in China
China's enthusiasm for teaching children to code is facing a new roadblock as organizations and students can no longer access the website of Scratch, the programming language developed at the MIT Media Lab.
Do I need VPN for web scraping
Most web scrapers need proxies to scrape without being blocked. However, proxies can be expensive and out of reach for many small web scrapers. One alternative to proxies is to use personal VPN services as proxy clients.

