
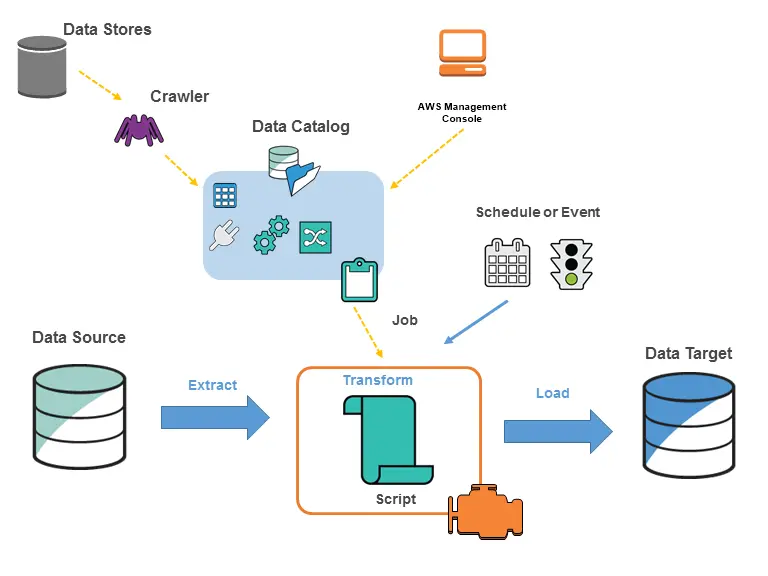
What is the use of crawler in glue
You can use a crawler to populate the AWS Glue Data Catalog with tables. This is the primary method used by most AWS Glue users. A crawler can crawl multiple data stores in a single run. Upon completion, the crawler creates or updates one or more tables in your Data Catalog.
Can we create a glue job without crawler
Now, you can create new catalog tables, update existing tables with modified schema, and add new table partitions in the Data Catalog using an AWS Glue ETL job itself, without the need to re-run crawlers.
What is a glue job in AWS
PDFRSS. An AWS Glue job encapsulates a script that connects to your source data, processes it, and then writes it out to your data target. Typically, a job runs extract, transform, and load (ETL) scripts. Jobs can also run general-purpose Python scripts (Python shell jobs.)
What is glue classifier
A classifier reads the data in a data store. If it recognizes the format of the data, it generates a schema. The classifier also returns a certainty number to indicate how certain the format recognition was. AWS Glue provides a set of built-in classifiers, but you can also create custom classifiers.
What is the difference between data catalog and crawler
Information in the Data Catalog is stored as metadata tables, where each table specifies a single data store. Typically, you run a crawler to take inventory of the data in your data stores, but there are other ways to add metadata tables into your Data Catalog.
What is database crawler
Web crawlers are automated software programs that browse the internet and systematically collect data from web pages. The process typically involves following hyperlinks from one page to another, and indexing the content of each page for later use.
Why are Glue jobs so slow
Some common reasons why your AWS Glue jobs take a long time to complete are the following: Large datasets. Non-uniform distribution of data in the datasets. Uneven distribution of tasks across the executors.
What is the difference between Glue and Glue crawler
You need AWS Glue Data Catalog to have the metadata information for source and target schemas to perform ETL operations. AWS Glue crawlers are scheduled or on-demand jobs that can query any given data store to extract scheme information and store the metadata in the AWS Glue Data Catalog.
What is AWS Glue data crawler
A crawler accesses your data store, extracts metadata, and creates table definitions in the AWS Glue Data Catalog. The Crawlers pane in the AWS Glue console lists all the crawlers that you create. The list displays status and metrics from the last run of your crawler.
How does glue work
Some glues are sticky polymers dissolved in water or another liquid, like common white glue. As the polymers dry, the liquid evaporates and the solid, sticky adhesive stays behind. Other glues help things stick because of a chemical reaction.
How does glue crawler detect schema
When the crawler runs, the crawler uses the custom classifier that you defined to find a match in the data store. The match with each classifier generates a certainty. If the classifier returns certainty=1.0 during processing, then the crawler is 100 percent certain that the classifier can create the correct schema.
How does glue data catalog work
The AWS Glue Data Catalog is an index to the location, schema, and runtime metrics of your data. You use the information in the Data Catalog to create and monitor your ETL jobs. Information in the Data Catalog is stored as metadata tables, where each table specifies a single data store.
How does crawler detect schema
Schema detection in crawler
During the first crawler run, the crawler reads either the first 1,000 records or the first megabyte of each file to infer the schema. The amount of data read depends on the file format and availability of a valid record.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How do you speed up glue crawler
Use an exclude pattern
An exclude pattern tells the crawler to skip certain files or paths. Exclude patterns reduce the number of files that the crawler must list, making the crawler run faster. For example, use an exclude pattern to exclude meta files and files that have already been crawled.
How long can a glue job run
This is the maximum time that a job run can consume resources before it is terminated and enters TIMEOUT status. This value overrides the timeout value set in the parent job. Streaming jobs do not have a timeout. The default for non-streaming jobs is 2,880 minutes (48 hours).
What is the hardest glue ever
The name of the world's strongest adhesive is DELO MONOPOX. This is a modified version of the high-temperature-resistant DELO MONOPOX HT2860. This epoxy resin forms a very dense network during heat curing.
Is glue gun stronger than super glue
Generally, super glue is stronger than hot glue. Super glue is a type of adhesive that sets quickly and forms a strong bond between two surfaces. Hot glue is a type of adhesive that is melted and then applied to two surfaces. It sets more slowly than super glue and does not form as strong of a bond.
How does Glue crawler determine schema
When the crawler runs, the crawler uses the custom classifier that you defined to find a match in the data store. The match with each classifier generates a certainty. If the classifier returns certainty=1.0 during processing, then the crawler is 100 percent certain that the classifier can create the correct schema.
How does Glue read data from S3
If you choose Recursive and select the sales folder as your S3 location, then AWS Glue Studio reads the data in all the child folders, but doesn't create partitions for year, month or day. Data format: Choose the format that the data is stored in. You can choose JSON, CSV, or Parquet.
Why is glue so strong
The cyanoacrylate molecules start to link and form chains, triggered by the water. They spin around in strands that form a super-strong plastic mesh, and they only stop when the glue becomes thick and hardens, and the molecular chains can't move.
What is the physics behind glue
When the molecules are similar, as in the case of two 'glue molecules,' the cohesive force causes the glue to stick to itself. When the molecules are dissimilar, as in the case of a glue molecule and a molecule of the substrate (the surface the glue is sticking to), the adhesive force holds the glue to the substrate.
How does a Glue crawler determine when to create partitions
When an AWS Glue crawler scans Amazon S3 and detects multiple folders in a bucket, it determines the root of a table in the folder structure and which folders are partitions of a table. The name of the table is based on the Amazon S3 prefix or folder name.
How does glue crawler determine schema
When the crawler runs, the crawler uses the custom classifier that you defined to find a match in the data store. The match with each classifier generates a certainty. If the classifier returns certainty=1.0 during processing, then the crawler is 100 percent certain that the classifier can create the correct schema.
How does glue read data from S3
If you choose Recursive and select the sales folder as your S3 location, then AWS Glue Studio reads the data in all the child folders, but doesn't create partitions for year, month or day. Data format: Choose the format that the data is stored in. You can choose JSON, CSV, or Parquet.

