
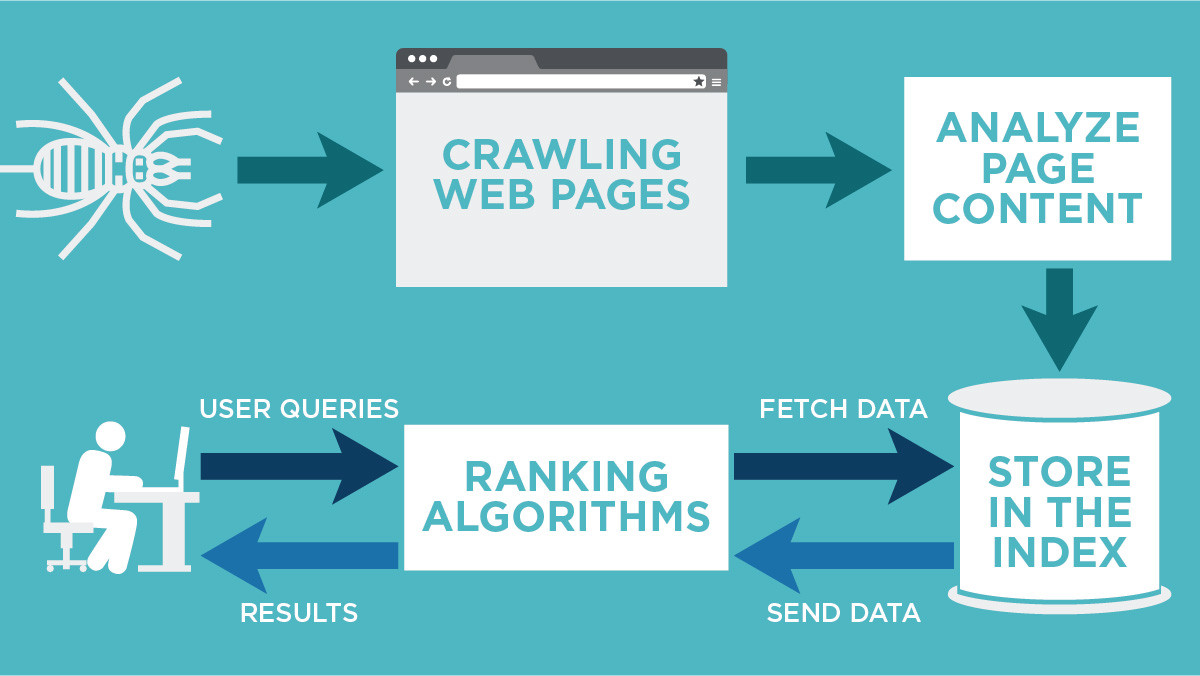
How does Google crawl and index websites
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
How does Google choose what to index
When Google visits your site, it detects new and updated pages and updates the Google index. To see which pages on your site are in the Google index, you can do a Google Web Search for "site:mywebsite.com". If you want more pages included in the Google index, use the Google Search Console to submit indexing requests.
How often does Google crawl index
It's a common question in the SEO community and although crawl rates and index times can vary based on a number of different factors, the average crawl time can be anywhere from 3-days to 4-weeks. Google's algorithm is a program that uses over 200 factors to decide where websites rank amongst others in Search.
What is the difference between crawled and indexed
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.
Why does Google crawl but not index pages
This product listing page was flagged as “Crawled — Currently Not Indexed”. This may be due to very thin content on the page. This page is likely either too thin for Google to think it's useful or there is so little content that Google considers it to be a duplicate of another page.
How does Google crawl a website
Most of our Search index is built through the work of software known as crawlers. These automatically visit publicly accessible web pages and follow links on those pages, much like you would if you were browsing content on the web.
How does Google index so fast
Caching: Google caches web pages, which means that it stores copies of frequently accessed pages on its own servers. This allows Google to quickly retrieve these pages and return them in search results without having to go to the original site each time.
What is the Google algorithm for SEO
What is a Google algorithm for SEO As mentioned previously, the Google algorithm partially uses keywords to determine page rankings. The best way to rank for specific keywords is by doing SEO. SEO essentially is a way to tell Google that a website or web page is about a particular topic.
Why does Google crawl but not index
This product listing page was flagged as “Crawled — Currently Not Indexed”. This may be due to very thin content on the page. This page is likely either too thin for Google to think it's useful or there is so little content that Google considers it to be a duplicate of another page.
Does Google automatically crawl
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
What happens first crawling or indexing
Crawling is the very first step in the process. It is followed by indexing, ranking (pages going through various ranking algorithms) and finally, serving the search results.
Why is crawled not indexed
The "Crawled – currently not indexed” error indicates that Google has already crawled these URLs, but hasn't indexed them yet. For most websites, this URL state is natural and will automatically resolve after Google's processed the URLs and added them to their index.
Why is my URL being crawled but not indexed
The 'crawled – currently not indexed' status within your page indexing report in Google Search Console means that Google has actively crawled the page on your website, but chosen not to include it in its index. This means that this page will not be showing up within Google's search engine results pages, for any query.
How does website indexing work
Website indexation is the process by which a search engine adds web content to its index. This is done by “crawling” webpages for keywords, metadata, and related signals that tell search engines if and where to rank content. Indexed websites should have a navigable, findable, and clearly understood content strategy.
How does Google crawl the web
Most of our Search index is built through the work of software known as crawlers. These automatically visit publicly accessible webpages and follow links on those pages, much like you would if you were browsing content on the web.
Does Google index lazy loading
So, short answer is "yes, but it depends". Google has repeatedly confirmed that it does index content that it can successfully render. This includes lazy load content.
What is Google’s ranking algorithm
PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. It is named after both the term "web page" and co-founder Larry Page. PageRank is a way of measuring the importance of website pages.
What are the top 5 Google algorithms related to SEO
Top 5 Major Google Algorithm Updates, Explained in 2023Penguin. The goal of Google Penguin is to lower the ranking of websites with suspicious-looking backlinks.Hummingbird. Google's Hummingbird algorithm gives a better understanding of search queries.RankBrain.Medic.Bert.
How do you solve crawled but not indexed
How to fix “Crawled ‐ currently not indexed”Provide high-quality content.Monitor your index coverage.Design a sound website structure.Limit your duplicate content.
Why is discovered but not indexed
If you see “Discovered – currently not indexed” in Google Search Console, it means Google is aware of the URL, but hasn't crawled and indexed it yet. It doesn't necessarily mean the page will never be processed. As their documentation says, they may come back to it later without any extra effort on your part.
How do I fix crawled but not indexed
Solution: Create a temporary sitemap. xml.Export all of the URLs from the “Crawled — currently not indexed” report.Match them up in Excel with redirects that have been previously set up.Find all of the redirects that have a destination URL in the “Crawled — currently not indexed” bucket.Create a static sitemap.
What does Google use to crawl a website
Googlebot
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
How does SEO crawling indexing work
In the SEO world, Crawling means “following your links”. Indexing is the process of “adding webpages into Google search”. Crawling is the process through which indexing is done. Google crawls through the web pages and index the pages.
Does index come first
It's best to insert the Index as the last section in the book, after the Bibliography or the References sections. If the book has no Bibliography or References, then you can put it after the Glossary section. If the book also has no Glossary, then you can put it after the Notes section.
What is indexing in crawling
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.

