
What does Google use to crawl a website
Googlebot
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
How often does Google crawl the web
It's a common question in the SEO community and although crawl rates and index times can vary based on a number of different factors, the average crawl time can be anywhere from 3-days to 4-weeks. Google's algorithm is a program that uses over 200 factors to decide where websites rank amongst others in Search.
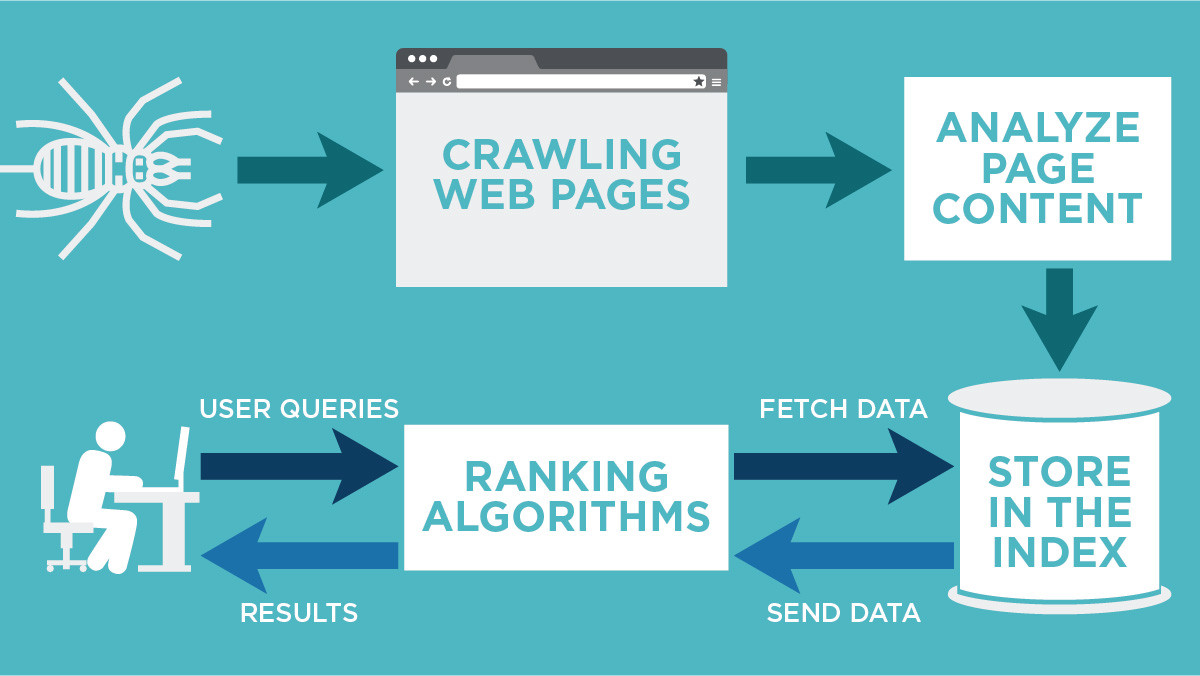
What is Google crawling
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
Does Google automatically crawl
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
Does Google crawl HTML
Google can only crawl your link if it's an <a> HTML element with an href attribute.
What technology is used to crawl websites
Bots
Answer: Bots
The correct answer to which technology search engines use to crawl websites is bots. To help you understand why this is the correct answer, we have put together this quick guide on bots, search engines and website crawls.
Why did Google stop crawling my site
Did you recently create the page or request indexing It can take time for Google to index your page; allow at least a week after submitting a sitemap or a submit to index request before assuming a problem. If your page or site change is recent, check back in a week to see if it is still missing.
How fast does Google crawl
Although it varies, it seems to take as little as 4 days and up to 6 months for a site to be crawled by Google and attribute authority to the domain. When you publish a new blog post, site page, or website in general, there are many factors that determine how quickly it will be indexed by Google.
How does Google crawl images
Google uses alt text along with computer vision algorithms and the contents of the page to understand the subject matter of the image. Also, alt text in images is useful as anchor text if you decide to use an image as a link.
How do I force Google to crawl
Here's Google's quick two-step process:Inspect the page URL. Enter in your URL under the “URL Prefix” portion of the inspect tool.Request reindexing. After the URL has been tested for indexing errors, it gets added to Google's indexing queue.
Does Google crawl with JavaScript
Google processes JavaScript web apps in three main phases: Crawling. Rendering. Indexing.
Can Google crawl CSS
“Googlebot can crawl the first 15MB of an HTML file or supported text-based file. Any resources referenced in the HTML such as images, videos, CSS, and JavaScript are fetched separately.
Which algorithm is used for web crawling
The first three algorithms given are some of the most commonly used algorithms for web crawlers. A* and Adaptive A* Search are the two new algorithms which have been designed to handle this traversal. Breadth First Search is the simplest form of crawling algorithm.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How long does it take for Google to crawl a site
Crawling can take anywhere from a few days to a few weeks. Be patient and monitor progress using either the Index Status report or the URL Inspection tool.
How does Google track if a place is busy
To determine popular times, wait times, and visit duration, Google uses aggregated and anonymized data from users who have opted in to Google Location History, which is off by default. Popular times, wait times, and visit duration are shown for the business if it gets enough visits from these users.
How does Google see my face
Face Match, the name Google calls the technology, keeps a digital eye out for faces passing by. When it recognizes yours, it displays content just for you: photos, messages, appointments and even how long of a commute you can expect. This mode of facial recognition offers a lot in the way of convenience.
Is Chrome blocking JavaScript
Enable JavaScript in Google Chrome
At the top right, click More Settings. At the bottom, click Show advanced settings. In the "Privacy" section, click Content settings. Select Allow all sites to run JavaScript (recommended) in the "JavaScript" section.
Which js does Google use
1. Angular. It is a framework written in TypeScript and developed by Google. It is an open-source web application framework used for developing single-page applications (SPA).
Can Google crawl JavaScript
As Googlebot can crawl and render JavaScript content, there is no reason (such as preserving crawl budget) to block it from accessing any internal or external resources needed for rendering. Doing so would only prevent your content from being indexed correctly, and thus, poor SEO performance.
Which language is best for web crawling
Top 5 programming languages for web scrapingPython. Python web scraping is the go-to choice for many programmers building a web scraping tool.Ruby. Another easy-to-follow programming language with a simple-to-understand syntax is Ruby.C++JavaScript.Java.
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
Is web scraping YouTube legal
Most data on YouTube is publicly accessible. Scraping public data from YouTube is legal as long as your scraping activities do not harm the scraped website's operations. It is important not to collect personally identifiable information (PII), and make sure that collected data is stored securely.
Why is Google not crawling my site
The Disallow tag (in your website's robots. txt file) blocks Google from crawling all the pages on your site. You can check for the disallow tag and make sure that there is no such tag present in the robots. txt that is preventing your page from being indexed.
Does Google track your every move
Google knows and captures every move, every click, every search… and a lot more for every user using Google services. However, the good news is that now you can also see what Google knows about you, and you can take control of what Google can learn about you in the future.

