
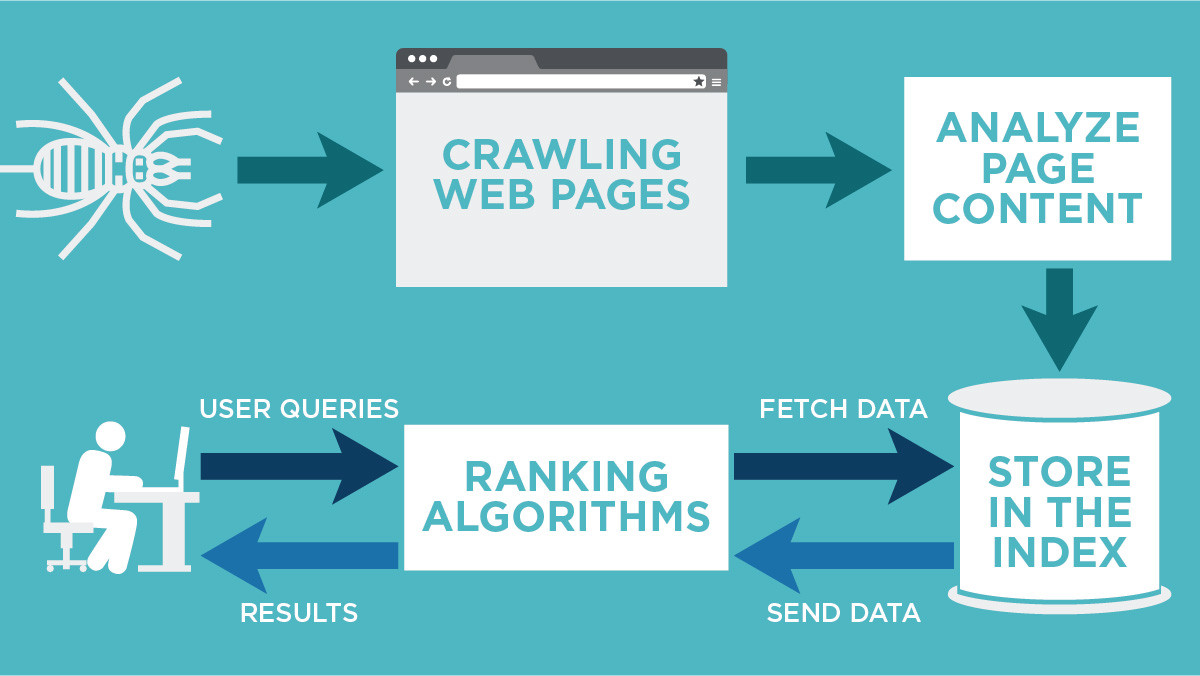
How does Google crawl a website
During the crawl, Google renders the page and runs any JavaScript it finds using a recent version of Chrome, similar to how your browser renders pages you visit. Rendering is important because websites often rely on JavaScript to bring content to the page, and without rendering Google might not see that content.
Does Google crawl all websites
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
How often does Google crawl your site
It's a common question in the SEO community and although crawl rates and index times can vary based on a number of different factors, the average crawl time can be anywhere from 3-days to 4-weeks. Google's algorithm is a program that uses over 200 factors to decide where websites rank amongst others in Search.
How long does it take for Google to crawl a site
Crawling can take anywhere from a few days to a few weeks. Be patient and monitor progress using either the Index Status report or the URL Inspection tool.
Is it legal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
How do I get Google to crawl my website daily
How do I get Google to recrawl my websiteGoogle's recrawling process in a nutshell.Request indexing through Google Search Console.Add a sitemap to Google Search Console.Add relevant internal links.Gain backlinks to updated content.
How do you know if a website can be crawled
If the URL is not within a Search Console property that you ownOpen the Rich Results test.Enter the URL of the page or image to test and click Test URL.In the results, expand the "Crawl" section.You should see the following results: Crawl allowed – Should be "Yes".
How do I force Google to crawl
Here's Google's quick two-step process:Inspect the page URL. Enter in your URL under the “URL Prefix” portion of the inspect tool.Request reindexing. After the URL has been tested for indexing errors, it gets added to Google's indexing queue.
Why is Google not crawling my site
The Disallow tag (in your website's robots. txt file) blocks Google from crawling all the pages on your site. You can check for the disallow tag and make sure that there is no such tag present in the robots. txt that is preventing your page from being indexed.
Can websites detect web scraping
If fingerprinting is enabled, the system uses browser attributes to help with detecting web scraping. If using fingerprinting with suspicious clients set to alarm and block, the system collects browser attributes and blocks suspicious requests using information obtained by fingerprinting.
How do I stop my website from crawling
Use Robots.
Robots. txt is a simple text file that tells web crawlers which pages they should not access on your website. By using robots. txt, you can prevent certain parts of your site from being indexed by search engines and crawled by web crawlers.
How do I trigger Google crawler
How to submit a URL for a recrawl in GSC Inspection ToolLog on to Google Search Console.Choose a property.Submit a URL from the website you want to get recrawled.Click the Request Indexing button.Regularly check the URL in the Inspection Tool.
How do I stop my website from being crawled
Use Robots.
Robots. txt is a simple text file that tells web crawlers which pages they should not access on your website. By using robots. txt, you can prevent certain parts of your site from being indexed by search engines and crawled by web crawlers.
Why is my website not being crawled
Google won't index your site if you're using a coding language in a complex way. It doesn't matter what the language is – it could be old or even updated, like JavaScript – as long as the settings are incorrect and cause crawling and indexing issues.
Does Google crawl hidden content
Well in general Google will only 'read' visible text. It will ignore hidden text, on the basis users dont see it either. So depending on how you implement the loading, if the text is still invisible when Googel 'renders' the page, Google will ignore the text.
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
Can you get banned for web scraping
The number one way sites detect web scrapers is by examining their IP address, thus most of web scraping without getting blocked is using a number of different IP addresses to avoid any one IP address from getting banned.
Is it illegal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
Is My website being crawled
To see if search engines like Google and Bing have indexed your site, enter "site:" followed by the URL of your domain. For example, "site:mystunningwebsite.com/". Note: By default, your homepage is indexed without the part after the "/" (known as the slug).
How do I stop Google from crawling my URL
noindex is a rule set with either a <meta> tag or HTTP response header and is used to prevent indexing content by search engines that support the noindex rule, such as Google.
How do I stop Google from crawling my pages
How to Prevent Google from Indexing Certain Web PagesUsing a “noindex” metatag. The most effective and easiest tool for preventing Google from indexing certain web pages is the “noindex” metatag.Using an X-Robots-Tag HTTP header.Using a robots.Using Google Webmaster Tools.
Why Google doesn’t index my website
Some of the most common causes of indexing issues are duplicate content without a proper canonical tag, blocked page access, incorrect robots. txt file, poorly implemented redirects, and rendering issues related to Javascript. In some cases, Google simply doesn't know that the page exists.
Does Google know my privacy
If You Use Google Products
And if you use Android (yeah, Google owns that too), then Google is also usually tracking: Every place you've been via Google Location Services. How often you use your apps, when you use them, where you use them, and who you use them to interact with. (This is just excessive by any measure.)
Is visibility hidden bad for SEO
Search engines aim to provide the best possible user experience by presenting relevant and useful content to users. Hidden web pages, which are pages that are not visible to users but are included on a website for the purpose of manipulating search engine rankings, go against this goal.
Do all websites grab your IP
The websites you visit, the apps you use, and even your ISP collect your IP address along with other personal information. However, individual users can also easily trace your IP address.

