
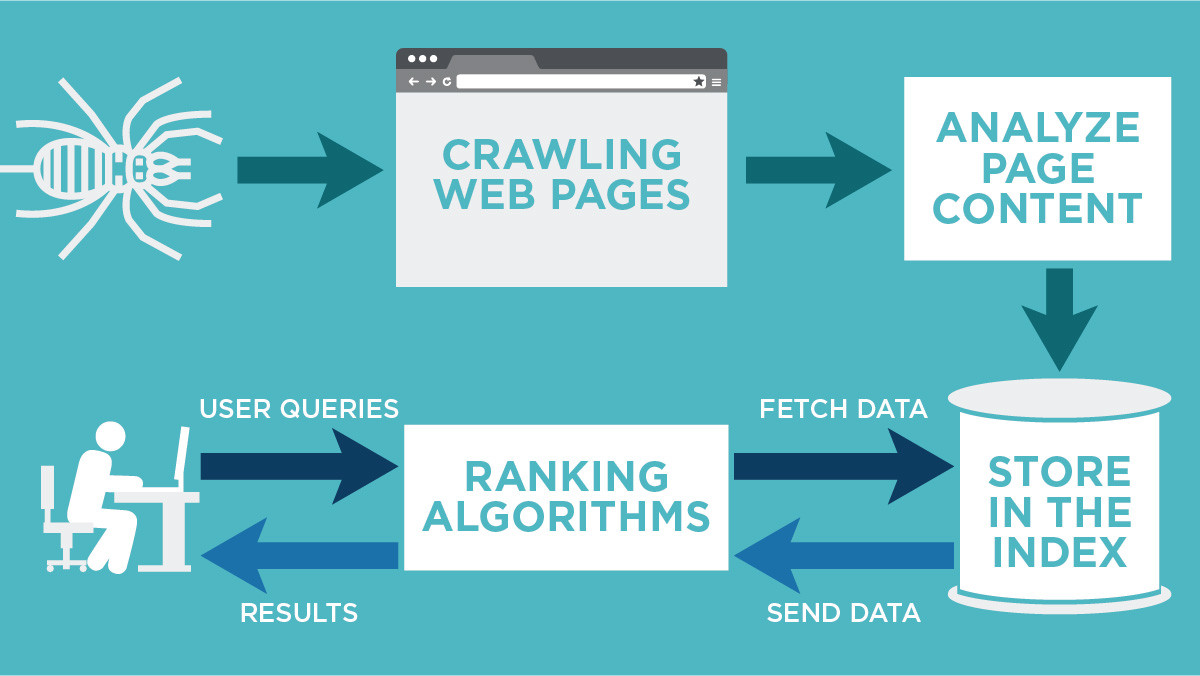
What is the Google crawling process
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions. Learn more.
How does Google SEO crawler work
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
How often will Google crawl my site
It's a common question in the SEO community and although crawl rates and index times can vary based on a number of different factors, the average crawl time can be anywhere from 3-days to 4-weeks. Google's algorithm is a program that uses over 200 factors to decide where websites rank amongst others in Search.
Does Google automatically crawl
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
Does Google crawl HTML
Google can only crawl your link if it's an <a> HTML element with an href attribute.
What is crawling algorithm
The basic web crawling algorithm fetches (i) a web page (II) Parse it to extract all linked URLs (III) For all the web URLs not seen before, repeat (I) -(III). The size of the web is large, so this web search engine can't cover all the websites in www.
What is the difference between Googlebot and crawler
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
How do I get my website crawled by Google
Here are the main ways to help Google find your pages:Submit a sitemap.Make sure that people know about your site.Provide comprehensive link navigation within your site.Submit an indexing request for your homepage.Sites that use URL parameters rather than URL paths or page names can be harder to crawl.
How do I know if Google is crawling my website
For a definitive test of whether your URL is appearing, search for the page URL on Google. The "Last crawl" date in the Page availability section shows the date when the page used to generate this information was crawled.
How do I increase my Google crawl rate
Without further adieu, here are some of the measures you can take to increase Google crawl rate.Add New Content To Your Website Regularly.Improve Your Website Load Time.Include Sitemaps To Increase Google Crawl Rate.Improve Server Response Time.Stay Away From Duplicate Content.Block Unwanted Pages via Robots.
Do Google crawlers run JavaScript
Google processes JavaScript web apps in three main phases: Crawling. Rendering. Indexing.
Does Googlebot crawl JavaScript
As Googlebot can crawl and render JavaScript content, there is no reason (such as preserving crawl budget) to block it from accessing any internal or external resources needed for rendering. Doing so would only prevent your content from being indexed correctly, and thus, poor SEO performance.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
What algorithm does web crawler use
Breadth-First Search Algorithm
Webcrawler is a very important application of the Breadth-First Search Algorithm.
Is Google a web crawler or web scraper
Google is most definitely a web crawler. They operate a web crawler with the name of Googlebot which searches for new websites, crawls them, and saves them in the massive search engine database. This is how Google powers its search engine and keeps it fresh with results from new websites.
Is web crawler same as web scraping
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
Why is Google not crawling my site
The Disallow tag (in your website's robots. txt file) blocks Google from crawling all the pages on your site. You can check for the disallow tag and make sure that there is no such tag present in the robots. txt that is preventing your page from being indexed.
How do I get Google to crawl my website daily
How do I get Google to recrawl my websiteGoogle's recrawling process in a nutshell.Request indexing through Google Search Console.Add a sitemap to Google Search Console.Add relevant internal links.Gain backlinks to updated content.
Does Google respect crawl delay
Google doesn't support the crawl-delay directive, so her crawlers will just ignore it.
How is crawl budget calculated
Search engines calculate crawl budget based on crawl limit (how often they can crawl without causing issues) and crawl demand (how often they'd like to crawl a site).
Do bots trigger JavaScript
These days, it's easy for attackers to create bots that can execute JavaScript (JS). Open-source libraries like Puppeteer, Playwright, and Selenium are used to instrument headless browsers, and bots as a service spawn browsers in the cloud on behalf of their customers—all of which can execute JS.
Do bots use JavaScript
The web server sends the challenge to each client as JavaScript code embedded in a web page. Since most popular browsers have a JavaScript stack, they will be able to understand and pass the challenge transparently. In contrast, bots typically do not have a JavaScript stack and, therefore, cannot pass the challenge.
How does Google crawl JavaScript
Once Google's resources allow, a headless Chromium renders the page and executes the JavaScript. Googlebot parses the rendered HTML for links again and queues the URLs it finds for crawling. Google also uses the rendered HTML to index the page.
Can Google crawl Ajax
The answer. As stated above, webmasters do not need to take any special action for Google to crawl their AJAX applications. “The AJAX crawling scheme was something we proposed in the early days of JavaScript sites, way back in 2009,” Mueller contextualized.
Is web scraping YouTube legal
Most data on YouTube is publicly accessible. Scraping public data from YouTube is legal as long as your scraping activities do not harm the scraped website's operations. It is important not to collect personally identifiable information (PII), and make sure that collected data is stored securely.

