
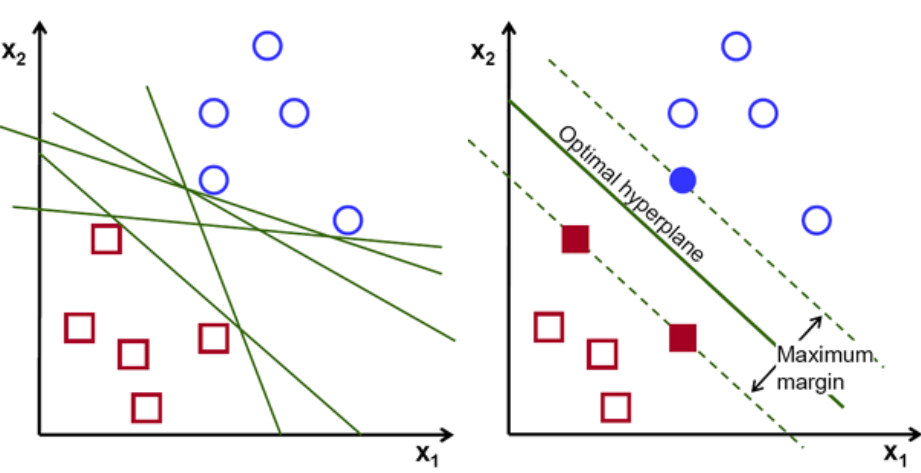
What is the difference between SVM and other classification
SVMs are different from other classification algorithms because of the way they choose the decision boundary that maximizes the distance from the nearest data points of all the classes. The decision boundary created by SVMs is called the maximum margin classifier or the maximum margin hyper plane.
How SVM is better than other classifiers
Advantages. SVM Classifiers offer good accuracy and perform faster prediction compared to Naïve Bayes algorithm. They also use less memory because they use a subset of training points in the decision phase. SVM works well with a clear margin of separation and with high dimensional space.
Why SVM is better than other algorithms
Advantages of SVM Classifier:
SVM works relatively well when there is a clear margin of separation between classes. SVM is more effective in high dimensional spaces and is relatively memory efficient. SVM is effective in cases where the dimensions are greater than the number of samples.
Why is SVM unique
The fact that training an SVM amounts to solving a convex quadratic programming problem means that the solution found is global, and that if it is not unique, then the set of global solutions is itself convex; furthermore, if the objec- tive function is strictly convex, the solution is guaranteed to be unique [1]1.
What is the difference between SVM and random forest classifier
For a classification problem Random Forest gives you probability of belonging to class. SVM gives you distance to the boundary, you still need to convert it to probability somehow if you need probability. For those problems, where SVM applies, it generally performs better than Random Forest.
What are some differences between SVMs and neural networks
An SVM possesses a number of parameters that increase linearly with the linear increase in the size of the input. A NN, on the other hand, doesn't. Even though here we focused especially on single-layer networks, a neural network can have as many layers as we want.
Why is SVM more accurate
In SVM, the data is classified into two classes and the hyper plane lies between those two classes. The advantage of SVM is that it also considers data being close to the opposite class and thus gives a reliable classification.
Why SVM has higher accuracy
The accuracy is high in linear separable since all the variables are included efficiently with separating hyperplane. SVMs are easily interpretable with an efficient classification which enhances the predictive accuracy on health problems. SVM is easy to implement and straightforward.
What is the main advantage of SVM
The advantages of SVM and support vector regression include that they can be used to avoid the difficulties of using linear functions in the high-dimensional feature space, and the optimization problem is transformed into dual convex quadratic programs.
Why SVM is better than Random Forest
Model accuracy by SVM classifier. It is because in this dataset, data is sparse and easy to classify, hence SVM works faster and provides better results. However, random forest also gives good results but does not match upto SVM for this particular dataset. The choice of algorithm depends upon the desired outcome.
What is the advantage of SVM over neural network
This is because the very first decision hyperplane in an SVM is guaranteed to be located between support vectors belonging to different classes. Neural networks don't offer this guarantee and, instead, position the initial decision function randomly.
Why SVM is better than random forest
Model accuracy by SVM classifier. It is because in this dataset, data is sparse and easy to classify, hence SVM works faster and provides better results. However, random forest also gives good results but does not match upto SVM for this particular dataset. The choice of algorithm depends upon the desired outcome.
Why SVM is better than Naive Bayes
Even though, NB gives good results when applied to short texts like tweets. For some datasets, NB may defeat other classifiers using feature selection. SVM is more powerful to address non-linear classification tasks. SVM generalizes well in high dimensional spaces like those corresponding to texts.
Why SVM is better than decision tree
SVM works better with large amount of data where there is more input training data. It can also fit any data changes because of n-dimensional classification. Easy to scale to large datasets. It is powerful in learning complicated rules and efficient in performance.
Why is SVM more accurate than Naive Bayes
Even though, NB gives good results when applied to short texts like tweets. For some datasets, NB may defeat other classifiers using feature selection. SVM is more powerful to address non-linear classification tasks. SVM generalizes well in high dimensional spaces like those corresponding to texts.
Why is SVM more accurate than KNN
KNN vs SVM :
SVM take cares of outliers better than KNN. If training data is much larger than no. of features(m>>n), KNN is better than SVM. SVM outperforms KNN when there are large features and lesser training data.
Why does SVM give better accuracy
It gives very good results in terms of accuracy when the data are linearly or non-linearly separable. When the data are linearly separable, the SVMs result is a separating hyperplane, which maximizes the margin of separation between classes, measured along a line perpendicular to the hyperplane.
How is SVM algorithm different from Naive Bayes
Naive Bayes Classification (NBC) and Support Vectore Machine (SVM) are techniques in data mining used to classify data or users opinion. The algorithm of NBC is very simple since it only use text frequency to compute the posterior probability for each classes. While SVM algorithm is more complex than NBC.
How is SVM different from Naive Bayes
Even though, NB gives good results when applied to short texts like tweets. For some datasets, NB may defeat other classifiers using feature selection. SVM is more powerful to address non-linear classification tasks. SVM generalizes well in high dimensional spaces like those corresponding to texts.
What is the main difference between SVM and kNN
While both algorithms yield positive results regarding the accuracy in which they classify the images, the SVM provides significantly better classification accuracy and classification speed than the kNN.
How is SVM algorithm different from linear regression
To sum up: Linear Regression has explicit decision and SVM finds approximate of real decision because of numerical(computational) solution.
What is the difference between SVM for linear and non linear classification
Linear SVM: When the data points are linearly separable into two classes, the data is called linearly-separable data. We use the linear SVM classifier to classify such data. Non-linear SVM: When the data is not linearly separable, we use the non-linear SVM classifier to separate the data points.
Is SVM better for classification or regression
SVM tries to finds the “best” margin (distance between the line and the support vectors) that separates the classes and this reduces the risk of error on the data, while logistic regression does not, instead it can have different decision boundaries with different weights that are near the optimal point.
Why SVM is better than linear regression
A. SVM regression or Support Vector Regression (SVR) is a machine learning algorithm used for regression analysis. It is different from traditional linear regression methods as it finds a hyperplane that best fits the data points in a continuous space, instead of fitting a line to the data points.

