
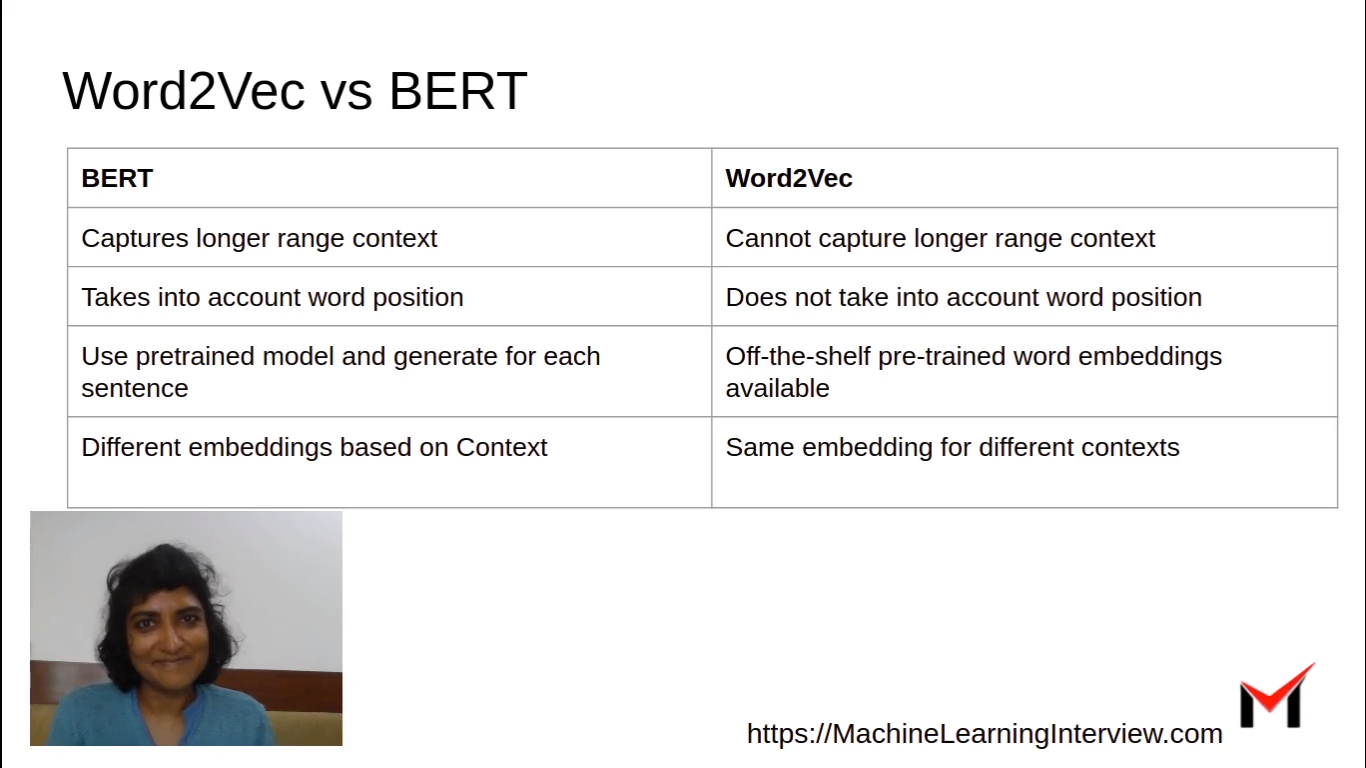
What is the advantage of BERT over Word2Vec
BERT offers an advantage over word embedding like Word2Vec, because while each word has a fixed representation under Word2Vec regardless of the context within which the word appears, BERT produces word representations that are dynamically informed by the words around them.
What is the difference between BERT and Word2Vec
Word2Vec embeddings do not take into account the word position. BERT model explicitly takes as input the position (index) of each word in the sentence before calculating its embedding.
Is BERT based on Word2Vec
BERT is a very different model architecture and cannot be compared with word2vec per se, but both can be used to represent text data.
Which word embedding algorithm is best
The choice of word embedding used is important to network performance; it is effectively the most important preprocessing step that you perform when performing an NLP task.Latent semantic analysis. Any algorithm that performs dimensionality reduction can be used to construct a word embedding.word2vec.GloVe.ELMO.BERT.
Is BERT the best model in NLP
Conclusion. BERT was able to improve the accuracy (or F1-score) on many Natural Language Processing and Language Modelling tasks. The main breakthrough that is provided by this paper is allowing the use of semi-supervised learning for many NLP tasks that allows transfer learning in NLP.
Which language model is better than BERT
XLNet is a large bidirectional transformer that uses improved training methodology, larger data and more computational power to achieve better than BERT prediction metrics on 20 language tasks. To improve the training, XLNet introduces permutation language modeling, where all tokens are predicted but in random order.
Can BERT be used for word embedding
Bert is an incredibly powerful tool for natural language processing tasks, and by training our own Bert word embedding model, we can generate high-quality word embeddings that capture the nuances of language specific to our own data.
What is the alternative to Word2vec
GloVe
In addition to word2vec, other popular implementations of word embedding are GloVe and FastText. The difference among these implementations is the type of algorithm used and the initial text corpus for training to create the model.
What is the best text embedding model
Top Pre-trained Models for Sentence EmbeddingDoc2Vec.SBERT.InferSent.Universal Sentence Encoder.
What is the alternative to Word2Vec
GloVe
In addition to word2vec, other popular implementations of word embedding are GloVe and FastText. The difference among these implementations is the type of algorithm used and the initial text corpus for training to create the model.
What is the most powerful NLP model
GPT-3
GPT-3 (Generative Pre-Trained Transformer 3) is a neural network-based language generation model. With 175 billion parameters, it's also one of the largest and most powerful NLP language models created to date. Like ChatGPT, GPT-3 was trained on a huge dataset of text.
What is better than BERT
MUM stands for Multitask Unified Model. This AI model is a step further than BERT and aims to solve more complex user search queries.
Is BERT good for text classification
BERT can be used for text classification tasks by fine-tuning the pre-trained model on a labeled dataset. Here is a general outline of the process: Preprocess the text data: This may include tasks such as lowercasing, tokenization, and removing stop words.
What is the weakness of word embedding
Historically, one of the main limitations of static word embeddings or word vector space models is that words with multiple meanings are conflated into a single representation (a single vector in the semantic space). In other words, polysemy and homonymy are not handled properly.
What is the difference between BERT sentence embedding and word embedding
Word embedding is often used in NLP tasks like translating languages, classifying texts, and answering questions. On the other hand, sentence embedding is a technique that represents a whole sentence or a group of words as a single fixed-length vector.
Is Word2vec outdated
Word2Vec and bag-of-words/tf-idf are somewhat obsolete in 2018 for modeling.
What are the disadvantages of Word2vec
Perhaps the biggest problem with word2vec is the inability to handle unknown or out-of-vocabulary (OOV) words. If your model hasn't encountered a word before, it will have no idea how to interpret it or how to build a vector for it. You are then forced to use a random vector, which is far from ideal.
Which is better BERT embeddings or FastText
The choice between the two models ultimately depends on the specific task at hand and the available resources, with BERT being a better choice for more complex and data-rich tasks, while FastText excels in applications that require speed and efficiency.
What is the alternative to word2vec
GloVe
In addition to word2vec, other popular implementations of word embedding are GloVe and FastText. The difference among these implementations is the type of algorithm used and the initial text corpus for training to create the model.
Why BERT is the best
BERT works well for task-specific models. The state of the art model, BERT, has been trained on a large corpus, making it easier for smaller, more defined nlp tasks. Metrics can be fine-tuned and be used immediately.
What is the difference between Bert sentence embedding and word embedding
Word embedding is often used in NLP tasks like translating languages, classifying texts, and answering questions. On the other hand, sentence embedding is a technique that represents a whole sentence or a group of words as a single fixed-length vector.
Which is the best sentence embedding technique
The choice of the best sentence embedding technique depends on various factors such as the specific task, data characteristics, and performance requirements. Several popular techniques include Universal Sentence Encoder (USE), BERT embeddings, InferSent, and Skip-Thought Vectors.
What are disadvantages of Word2Vec
Perhaps the biggest problem with word2vec is the inability to handle unknown or out-of-vocabulary (OOV) words. If your model hasn't encountered a word before, it will have no idea how to interpret it or how to build a vector for it. You are then forced to use a random vector, which is far from ideal.
What is the weakness of Word2vec
Word2vec ChallengesInability to handle unknown or OOV words.No shared representations at sub-word levels.Scaling to new languages requires new embedding matrices.Cannot be used to initialize state-of-the-art architectures.
What is the problem with Word2vec
Word2Vec cannot handle out-of-vocabulary words well. It assigns a random vector representation for OOV words which can be suboptimal. It relies on local information of language words. The semantic representation of a word relies only on its neighbours & can prove suboptimal.

