
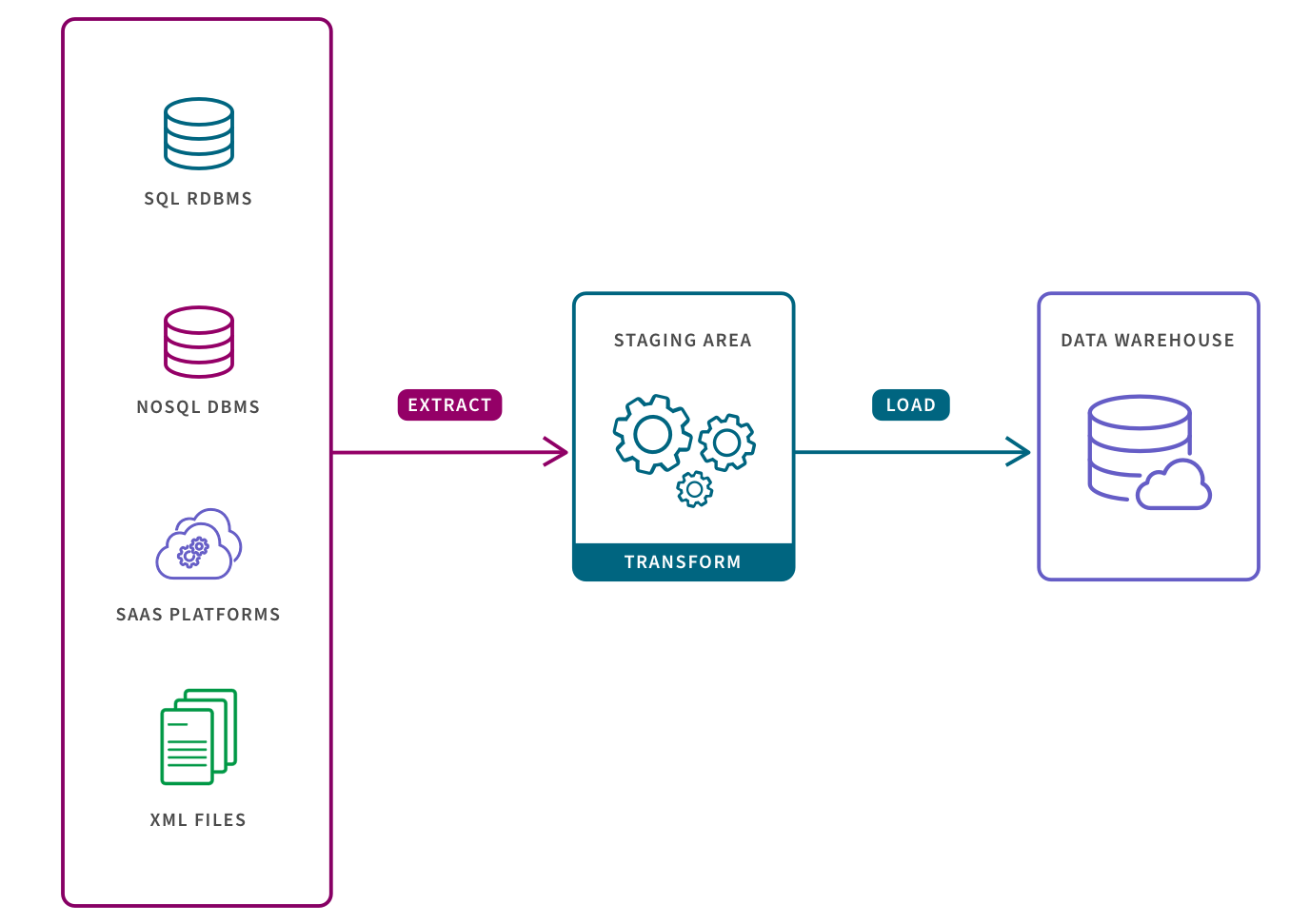
What is the difference between ETL pipeline and data pipeline
But what's the difference Both data pipelines and ETL are responsible for transferring data between sources and storage solutions, but they do so in different ways. Data pipelines work with ongoing data streams in real time, while ETL focuses more on individual “batches” of data for more specific purposes.
What is ETL and data pipeline
A data pipeline refers to the entire set of processes applied to data as it moves from one system to another. As the term “ETL pipeline” refers to the processes of extraction, transforming, and loading of data into a database such as a data warehouse, ETL pipelines qualify as a type of data pipeline.
What is pipeline vs data pipeline
ETL pipeline includes a series of processes that extracts data from a source, transform it, and load it into the destination system. On the other hand, a data pipeline is a somewhat broader terminology that includes an ETL pipeline as a subset.
What is considered a data pipeline
What is a data pipeline A data pipeline is a method in which raw data is ingested from various data sources and then ported to data store, like a data lake or data warehouse, for analysis. Before data flows into a data repository, it usually undergoes some data processing.
Is AWS data pipeline an ETL tool
AWS Data Pipeline Product Details
As a managed ETL (Extract-Transform-Load) service, AWS Data Pipeline allows you to define data movement and transformations across various AWS services, as well as for on-premises resources.
Is ELT a data pipeline
ELT stands for "extract, load, and transform" — the processes a data pipeline uses to replicate data from a source system into a target system such as a cloud data warehouse.
Is ETL part of data pipeline
An ETL pipeline is simply a data pipeline that uses an ETL strategy to extract, transform, and load data. Here data is typically ingested from various data sources such as a SQL or NoSQL database, a CRM or CSV file, etc.
What are the two types of pipelines in a digital system
Static vs Dynamic Pipelining
The static pipeline executes the same type of instructions continuously. Frequent change in the type of instruction may vary the performance of the pipelining. Dynamic pipeline performs several functions simultaneously. It is a multifunction pipelining.
Is SQL a data pipeline
The SQL query runs a Dataflow pipeline, and the results of the pipeline are written to a BigQuery table. To run a Dataflow SQL job, you can use the Google Cloud console, the Google Cloud CLI installed on a local machine, or Cloud Shell.
What are examples of data pipelines
7 Examples of Data PipelinesChange Data Capture Pipeline.Migration Pipeline From an On-Premise Database to a Cloud Warehouse.Streaming Pipeline from Kafka to Elasticsearch on AWS.Reverse ETL Pipeline Example.Pipeline Using A Fragment.Pipeline from Local File Storage to Local File Storage.
What is the best ETL tool for AWS
Which is the best tool for ETL in AWSFivetran. Fivetran is a cloud-based data integration platform that specializes in automating data pipelines.AWS Glue. AWS Glue is a widely used ETL tool that is managed completely by AWS.AWS Data Pipeline.Stitch Data.Talend.Informatica.Integrate .
Which tool is used for data pipeline
Stitch is a data pipeline tool that lets you connect data from databases like MySQL and SaaS apps like Salesforce and Zendesk — and replicates them in your preferred cloud data warehouses, all without coding.
Is ELT replacing ETL
Whether ELT replaces ETL depends on the use case. While ELT is adopted by businesses that work with big data, ETL is still the method of choice for businesses that process data from on-premises to the cloud. It is obvious that data is expanding and pervasive.
Can ETL process also use the pipelining concept
ETL process can also use the pipelining concept i.e. as soon as some data is extracted, it can transformed and during that period some new data can be extracted. And while the transformed data is being loaded into the data warehouse, the already extracted data can be transformed.
Does ETL come under data engineering
ETL, which stands for extract, transform, and load, is the process data engineers use to extract data from different sources, transform the data into a usable and trusted resource, and load that data into the systems end-users can access and use downstream to solve business problems.
What are the three types of pipelines
There are essentially three major types of pipelines along the transportation route: gathering systems, transmission systems, and distribution systems.
Is SQL considered ETL
Python, Ruby, Java, SQL, and Go are all popular programming languages in ETL.
What are the 2 types of pipelines available
Declarative versus Scripted Pipeline syntax
Declarative and Scripted Pipelines are constructed fundamentally differently.
Does AWS have an ETL tool
AWS Glue Studio offers Visual ETL, Notebook, and code editor interfaces, so users have tools appropriate to their skillsets. With Interactive Sessions, data engineers can explore data as well as author and test jobs using their preferred IDE or notebook.
Why is ELT preferred over ETL
The primary advantage of ELT over ETL relates to flexibility and ease of storing new, unstructured data. With ELT, you can save any type of information—even if you don't have the time or ability to transform and structure it first—providing immediate access to all of your information whenever you want it.
Is ETL the same as data migration
ETL represents Extract, Transform and Load, which is a cycle used to gather data from different sources, change the data relying upon business rules/needs and burden the information into an objective data set. Data migration is the way toward moving information starting with one framework then onto the next.
What is the pipelining process also called as
Pipelining is a technique used in computer architecture to increase the performance of processors. It allows multiple instructions to be executed at the same time by dividing them into smaller sub-tasks and processing them in parallel. The pipelining process is also referred to as Assembly line operation.
What is the difference between ETL and data engineering
ETL developers are a part of the data engineering team. They are mainly responsible for performing the ETL process, i.e., extract, transform, and load functions while data moves from source to target location. Data engineers are responsible for designing and maintaining data pipelines and infrastructures.
Is ETL part of data analyst
ETL is the base for analyzing data and creating machine learning (ML) workflows. Various business rules are applied, then this process cleanses entries and organizes each so this data can also handle advanced analysis and address multiple business intelligence (BI) requirements.
What are 5 stage pipelines
This enables several operations to take place simultaneously, and the processing and memory systems to operate continuously. A five-stage (five clock cycle) ARM state pipeline is used, consisting of Fetch, Decode, Execute, Memory, and Writeback stages.

