
Is Google a web crawler
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.
Is a search engine a web crawler
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
Does Google use spiders or crawlers
Google uses crawlers and fetchers to perform actions for its products, either automatically or triggered by user request. "Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another.
What is Google also called web crawler
Google is most definitely a web crawler. They operate a web crawler with the name of Googlebot which searches for new websites, crawls them, and saves them in the massive search engine database.
Is Google Web scraping
Yes, Google scrapes data from other websites too, but before we go into that, let's explain what happens before any website appearing on the Google SERP (Search engine Result Page) shows up on your result. SERP means extracting data from different engines (Google, Bing, Yahoo, etc.) Search Engine Result Pages.
Does Google crawl HTML
Google can only crawl your link if it's an <a> HTML element with an href attribute.
Is Google a search engine or a website
Google is a fully-automated search engine that uses software known as "web crawlers" that explore the web on a regular basis to find sites to add to our index.
How does Google crawl the web
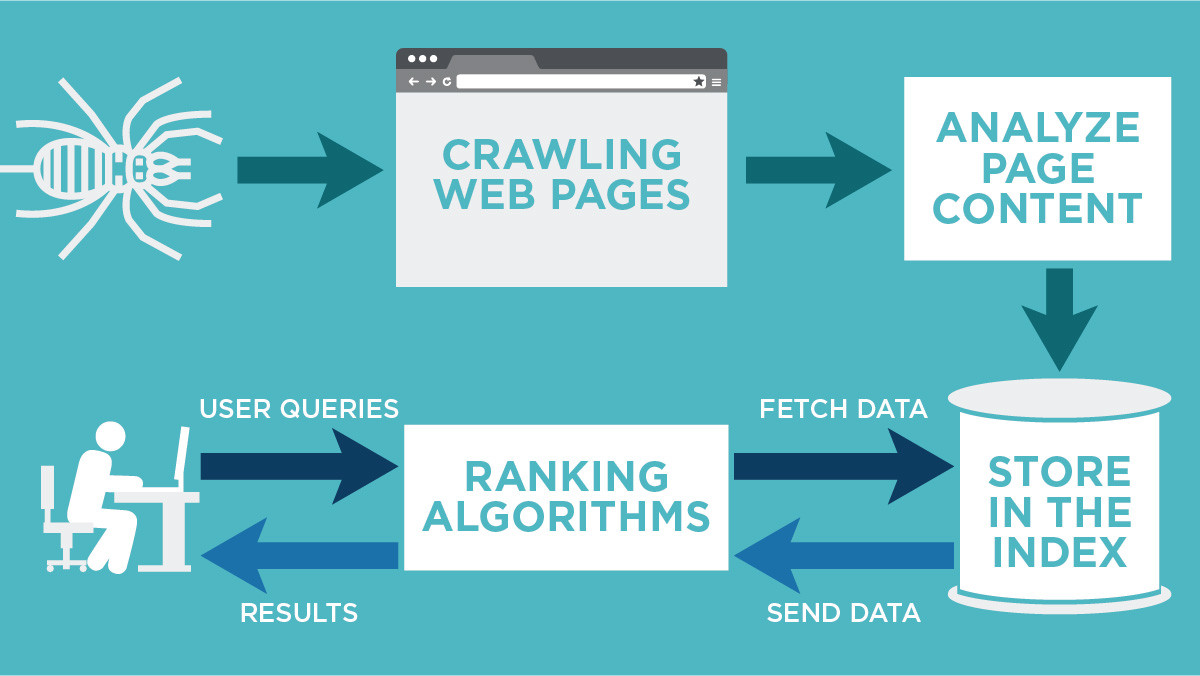
Most of our Search index is built through the work of software known as crawlers. These automatically visit publicly accessible webpages and follow links on those pages, much like you would if you were browsing content on the web.
How many web crawlers does Google use
As for Google, there are more than 15 different types of crawlers, and the main Google crawler is called Googlebot. Googlebot performs both crawling and indexing, that's why we'll take a closer look at how it works.
What is an example of a web crawler
Examples of web crawlers
Amazonbot is the Amazon web crawler. Bingbot is Microsoft's search engine crawler for Bing. DuckDuckBot is the crawler for the search engine DuckDuckGo. Googlebot is the crawler for Google's search engine.
Is Bing a web crawler
Bing is a search engine owned by Microsoft and Bingbot is their standard crawler that handles most of the sites' crawling on a daily basis, for both desktop and mobile web! Bing operates five main crawlers: Bingbot. The standard crawler in charge of crawling and indexing sites.
Is it legal to scrape Google search results
As a matter of fact, scraping publicly available data on the internet – including Google SERP data – is legal.
Does Google ban scraping
If you would like to fetch results from Google Search on your personal computer and browser, Google will eventually block your IP when you exceed a certain number of requests. You'll need to use different solutions to scrape Google SERP without being banned.
Can Google crawl CSS
“Googlebot can crawl the first 15MB of an HTML file or supported text-based file. Any resources referenced in the HTML such as images, videos, CSS, and JavaScript are fetched separately.
What kind of website is Google
Google Search (also known simply as Google or Google.com) is a search engine provided and operated by Google. Handling more than 3.5 billion searches per day, it has a 92% share of the global search engine market. It is the most-visited website in the world.
What type of search engine is Google
These types of search engines use a "spider" or a "crawler" to search the Internet. The crawler digs through individual web pages, pulls out keywords and then adds the pages to the search engine's database. Google and Yahoo are examples of crawler search engines.
How many web crawlers does Google have
Googlebot is the generic name for Google's two types of web crawlers: Googlebot Desktop: a desktop crawler that simulates a user on desktop. Googlebot Smartphone: a mobile crawler that simulates a user on a mobile device.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Is Yahoo a web crawler
Search engines like Google, Bing, and Yahoo use crawlers to properly index downloaded pages so that users can find them faster and more efficiently when searching. Without web crawlers, there would be nothing to tell them that your website has new and fresh content.
How does Google web crawler work
How do web crawlers work A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
Does Google use web scraping
Yes, Google scrapes data from other websites too, but before we go into that, let's explain what happens before any website appearing on the Google SERP (Search engine Result Page) shows up on your result. SERP means extracting data from different engines (Google, Bing, Yahoo, etc.) Search Engine Result Pages.
Does Google use data scraping
The process of entering a website and extracting data in an automated fashion is also often called "crawling". Search engine's like Google, Bing, Yahoo or Sogou get almost all their data from automated crawling bots. Search engines are an integral part of the modern online ecosystem.
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
How do I crawl Google without being blocked
8 ways to avoid getting blocked while scraping GoogleRotate your IPs.Set real user agents.Use a headless browser.Implement CAPTCHA solvers.Reduce the scraping speed & set intervals in between requests.Detect website changes.Avoid scraping images.Scrape data from Google cache.
Does Google crawl JavaScript
Googlebot processes JavaScript web pages in three phases: crawling, rendering, and indexing.

