
How does web crawling work
A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
What is involved in creating a web crawler
Here are the basic steps to build a crawler:
Step 1: Add one or several URLs to be visited. Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread. Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
What is the difference between spider and crawler
Spider- A browser like program that downloads web pages. Crawler- A program that automatically follows all of the links on each web page. Robots- An automated computer program that visits websites and perform predefined tesk.
What is a spider on a website
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
What is web scrape vs crawl
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
What is Spidering in cyber security
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering).
What are spiders crawlers and bots
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web, typically for the purpose of Web indexing (web spidering). (Source: wikipedia.org)
What is spider vs crawler vs scraper
A crawler(or spider) will follow each link in the page it crawls from the starter page. This is why it is also referred to as a spider bot since it will create a kind of a spider web of pages. A scraper will extract the data from a page, usually from the pages downloaded with the crawler.
What are spiders used for in digital marketing
Web crawlers or web browser bots are also known as "spiders" in the context of digital marketing. It's an automated software application that routinely examines internet sites and internet pages in order to gather data and create an inventory for websites such as Google, Amazon, Alibaba, and others.
Why do spiders make web designs
Stabilimenta are thought to have purposes including making the web more visible to non-target species (like humans!) so the web is a little more protected from accidental destruction; camouflage so that the resting spider itself is hidden within the design; or attracting prey to a certain part of the web.
What is the web spider called
A member of the Araneidae family, the garden orb-weaver or garden cross spider (Araneus diadematus) is probably the best-known orb-web spider.
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
Is scraping TikTok legal
Scraping publicly available data on the web, including TikTok, is legal as long as it complies with applicable laws and regulations, such as data protection and privacy laws.
What is spider in web scraping
Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items).
What is Spidering and why is it used
Web search engines and some other websites use Web crawling or spidering software to update their web content or indices of other sites' web content. Web crawlers copy pages for processing by a search engine, which indexes the downloaded pages so that users can search more efficiently.
What are spiders or robots
Also known as Robot, Bot, or Spider. These are programs used by search engines to explore the Internet and automatically download web content available on websites.
How do Google spiders work
Google Spider is basically Google's crawler. A crawler is a program/algorithm designed by search engines to crawl and track websites and web pages as a way of indexing the internet. When Google visits your website for tracking/indexing purposes, this process is done by Google's Spider crawler.
What is the difference between a web crawler and a web scraper
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
What are robots and spiders
Also known as Robot, Bot, or Spider. These are programs used by search engines to explore the Internet and automatically download web content available on websites.
Why are spiders used for
Because of their abundance, they are the most important predators of insects. Spiders have been used to control insects in apple orchards in Israel and rice fields in China. Large numbers of spiders have also been observed feeding on insects in South American rice fields and in fields of various North American crops.
How do spiders make web patterns
As the spider moves back and forth, it adds more threads, strengthening the web and creating a pattern. Lines that go from the center of the web outward are called "radial lines." They support the web. Threads that go around and around the web are called "orb lines."
Why do spiders make patterns
Stabilimenta are thought to have purposes including making the web more visible to non-target species (like humans!) so the web is a little more protected from accidental destruction; camouflage so that the resting spider itself is hidden within the design; or attracting prey to a certain part of the web.
How do spiders make a web
First it connects. Two end points like two branches with silk threads forming a bridge. It then releases a loose thread from its center it adds a new thread pulling it to form a y shape.
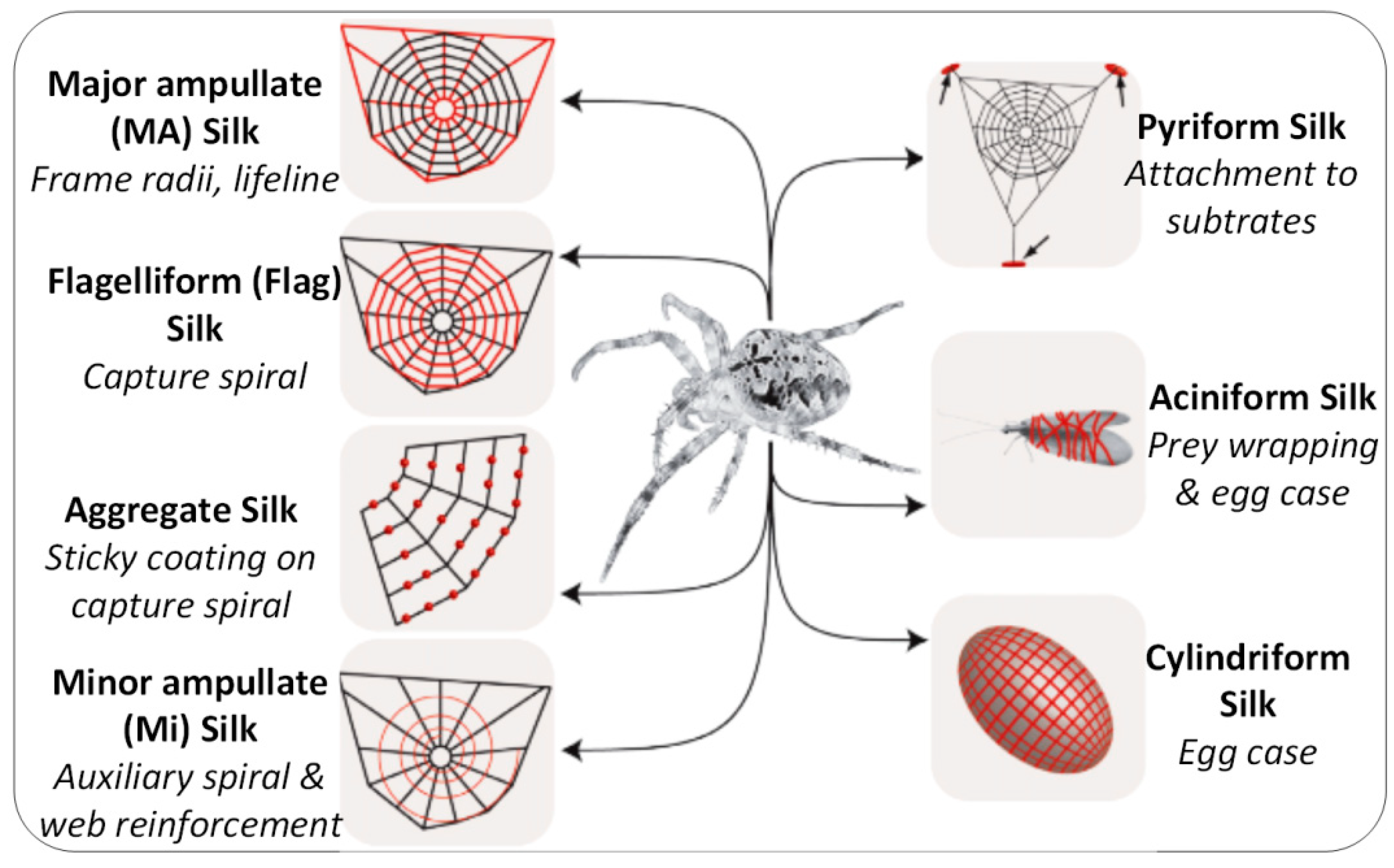
What is spider web silk called
This particular silk is further used by spiders as a lifeline (or roping thread) which has to be ready at hand to escape predators—it is therefore always dragged, hence the nickname “dragline silk.” The capture spiral of an orb web comprises fibers of only one type of protein which is produced in the flagelliform (Flag …

