
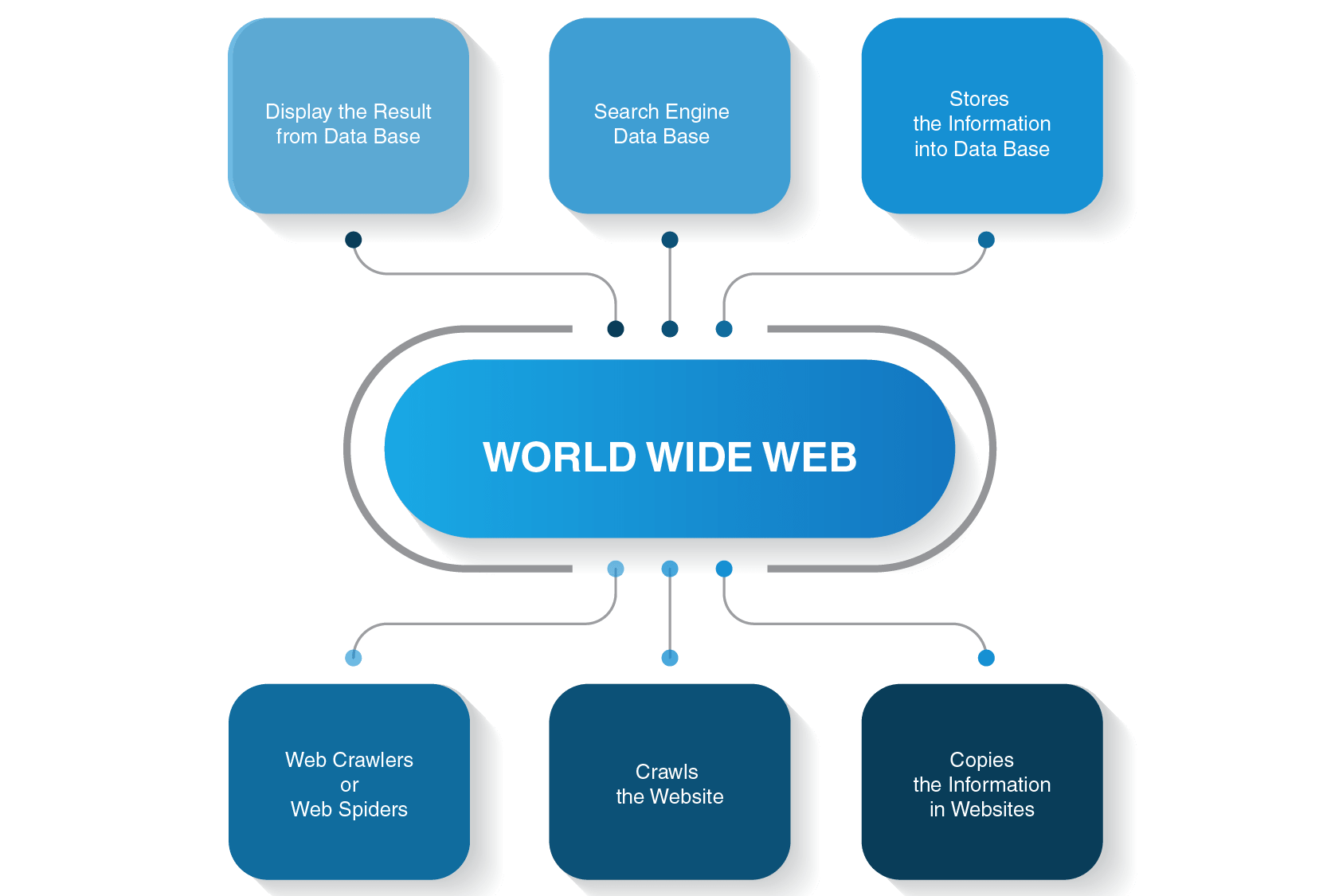
How are websites crawled
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
What is an example of web crawling
1. GoogleBot. As the world's largest search engine, Google relies on web crawlers to index the billions of pages on the Internet. Googlebot is the web crawler Google uses to do just that.
Bản lưu
What does Google use to crawl a website
Googlebot
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
What software program crawls the web
20 Best Web Crawling Tools & Software in 2023
| Best for | Price | |
|---|---|---|
| Apache Nutch | Writing scalable web crawlers | Free web crawling tool |
| Outwit Hub | Small projects | Free version available. Paid plan starts at $110/month |
| Cyotek WebCopy | Users with a tight budget | Free web crawling tool |
| WebSPHINX | Browsing offline | Free web crawling tool |
How do crawlers find websites
Because it is not possible to know how many total webpages there are on the Internet, web crawler bots start from a seed, or a list of known URLs. They crawl the webpages at those URLs first. As they crawl those webpages, they will find hyperlinks to other URLs, and they add those to the list of pages to crawl next.
Does Google crawl HTML
Google can only crawl your link if it's an <a> HTML element with an href attribute.
What is crawling website for SEO
What Is Crawling In SEO. In the context of SEO, crawling is the process in which search engine bots (also known as web crawlers or spiders) systematically discover content on a website. This may be text, images, videos, or other file types that are accessible to bots.
How do I identify a web crawler
Crawler identification
Web crawlers typically identify themselves to a Web server by using the User-agent field of an HTTP request. Web site administrators typically examine their Web servers' log and use the user agent field to determine which crawlers have visited the web server and how often.
What is crawling in SEO
What Is Crawling In SEO. In the context of SEO, crawling is the process in which search engine bots (also known as web crawlers or spiders) systematically discover content on a website. This may be text, images, videos, or other file types that are accessible to bots.
How do I crawl a website fast
A couple of simple tips to increase your site's crawl speed:Using the methods above, find and fix all the errors.Make sure your site is fast.Add an XML sitemap to your site and submit it to the search engines.If all of that fails to improve your crawl speed, start link building!
Can I crawl any website
As long as you are not crawling at a disruptive rate and the source is public you should be fine. I suggest you check the websites you plan to crawl for any Terms of Service clauses related to scraping of their intellectual property. If it says “no scraping or crawling”, maybe you should respect that.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How are web crawlers made
Here are the basic steps to build a crawler:
Step 1: Add one or several URLs to be visited. Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread. Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
Does Google crawl with JavaScript
Google processes JavaScript web apps in three main phases: Crawling. Rendering. Indexing.
Does Googlebot crawl JavaScript
As Googlebot can crawl and render JavaScript content, there is no reason (such as preserving crawl budget) to block it from accessing any internal or external resources needed for rendering. Doing so would only prevent your content from being indexed correctly, and thus, poor SEO performance.
What is crawling in web scraping
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web.
How do I increase my website crawling
Add New Content To Your Website Regularly
Websites that update content on a regular basis have a good chance of getting crawled frequently. To improve Google crawl rate, it is recommended that you post content three times in a week. Instead of adding new web pages, you can provide fresh content via a blog.
Can web crawler be detected
Most website administrators use the User-Agent field to identify web crawlers. However, some other common methods will detect your crawler if it's: Sending too many requests: If a crawler sends too many requests to a server, it may be detected and/or blocked.
What is web crawling and SERP
The crawling process of Google works by finding out your website on the internet and crawl the content of the web pages. It also follows links on the site and creates and index of the websites that were crawled. The indexing is another part of Google SERP process.
What is web crawling or scraping
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
Is it illegal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Can bots crawl my site
As a website owner, you want to make sure that your site is secure and protected from malicious bots and crawlers. While bots can serve useful purposes, such as indexing your site for search engines, many bots are designed to scrape your content, use your resources, or even harm your site.
Is scraping TikTok legal
Scraping publicly available data on the web, including TikTok, is legal as long as it complies with applicable laws and regulations, such as data protection and privacy laws.
Are web crawlers illegal
United States: There are no federal laws against web scraping in the United States as long as the scraped data is publicly available and the scraping activity does not harm the website being scraped.

