
What is crawling in database
Crawling refers to following the links on a page to new pages, and continuing to find and follow links on new pages to other new pages. A web crawler is a software program that follows all the links on a page, leading to new pages, and continues that process until it has no more new links or pages to crawl.
How does data crawling work
How do web crawlers work A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
What is meant by crawling process
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
What is crawl in software
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
What is data scraping and crawling
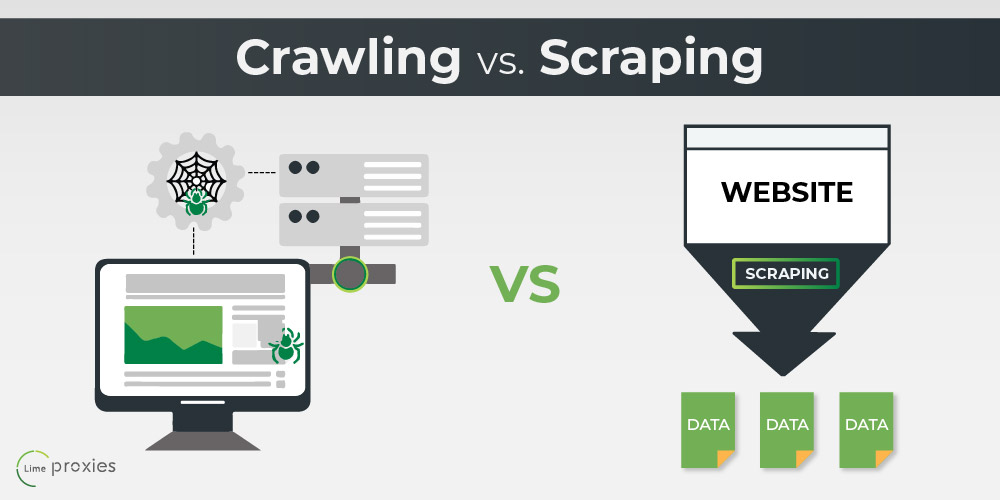
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web.
Does Google crawl databases
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
What is crawler and how it works
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What does crawl mean in Python
Web crawling is a powerful technique to collect data from the web by finding all the URLs for one or multiple domains. Python has several popular web crawling libraries and frameworks. In this article, we will first introduce different crawling strategies and use cases.
Why is crawling important
These movements help build strength in their upper arms and shoulders. Crawling also develops an infant's upper and lower body coordination. We all have front-to-back and top-to-bottom invisible lines across our body, and crawling requires your brain to learn to coordinate movement across these lines.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How to do data crawling
Here are the basic steps to build a crawler:Step 1: Add one or several URLs to be visited.Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread.Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
What is crawling vs indexing
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
Does Google crawl all websites
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
What does Google use for database
Google primarily uses Bigtable. Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size. For more information, download the document from here. Google also uses Oracle and MySQL databases for some of their applications.
Why do we need crawler
With Crawlers, you can quickly and easily scan your data sources, such as Amazon S3 buckets or relational databases, to create metadata tables that capture the schema and statistics of your data.
What is the advantage of crawler
The main advantage of a crawler is that they can move on site and perform lifts with very little set-up, as the crane is stable on its tracks with no outriggers. In addition, a crawler crane is capable of traveling with a load.
What is called crawl
a. : to move on one's hands and knees. The baby crawled toward her mother. b. : to move slowly in a prone position without or as if without the use of limbs.
What is crawl with example
To crawl is to move slowly across the floor on your hands and knees. Before they learn to walk, most babies crawl. You might crawl around looking for a lost earring, or watch a spider crawl across your ceiling.
Why is crawling longer better
Crawling Improves Their Physical Capabilities
This help to improve their: Gross motor skills (the larger movements they make) Fine motor skills. Coordination.
Why is crawling important in research
Research has shown that baby crawling increases hand-eye coordination, gross and fine motor skills (large and refined movements), balance, and overall strength.
Is data crawling ethical
Crawlers are involved in illegal activities as they make copies of copyrighted material without the owner's permission. Copyright infringement is one of the most important legal issues for search engines that need to be addressed upon.
What is the difference between scrape and crawl data
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
What is crawling vs indexing vs ranking
Indexing – Once a page is crawled, search engines add it to their database. For Google, crawled pages are added to the Google Index. Ranking- After indexing, search engines rank pages based on various factors. In fact, Google weighs pages against its 200+ ranking factors before ranking them.
What is data scraping vs data crawling
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
Is it illegal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.

