
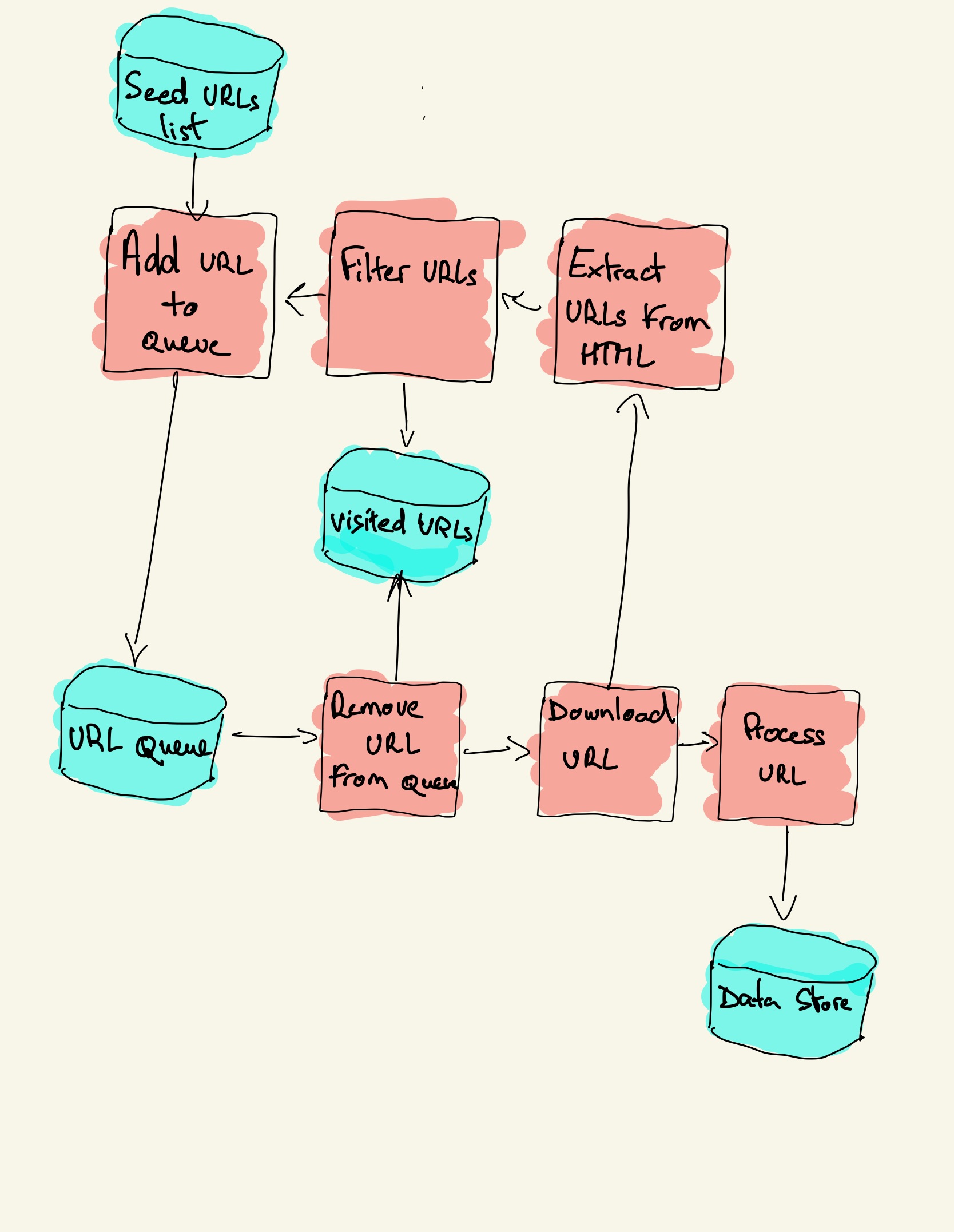
What is Python crawler
Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code. A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue.
How to use web crawler in Python
The basic workflow of a general web crawler is as follows:Get the initial URL.While crawling the web page, we need to fetch the HTML content of the page, then parse it to get the URLs of all the pages linked to this page.Put these URLs into a queue;
What is scrapy crawl
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages.
What is powerful web scraping and crawling with Python
Scrapy is a free and open source web crawling framework, written in Python. Scrapy is useful for web scraping and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
What is a crawler
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
Why is crawler used
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How does web crawling work
Web crawlers systematically browse webpages to learn what each page on the website is about, so this information can be indexed, updated and retrieved when a user makes a search query. Other websites use web crawling bots while updating their own web content.
What is crawling method
What is search engine crawling Crawling is the discovery process in which search engines send out a team of robots (known as crawlers or spiders) to find new and updated content. Content can vary — it could be a webpage, an image, a video, a PDF, etc. — but regardless of the format, content is discovered by links.
What is data crawling
What is Data crawling Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
What does crawling mean in data
What is Data crawling Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
How does crawl work
A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
What is a crawler coding
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
What is crawler mode
Crawl Control is designed for driving on difficult terrain at low speeds. It assists the driver by controlling acceleration and braking, allowing the driver to focus on steering.
What is data crawl
Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
Are web bots illegal
Are spam bots illegal While spambots are not in themselves illegal, their botmasters may be punished for using them for illegal purposes. An example of this might be using spambots to distribute links to a phishing scam.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
What is a crawler in programming
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering).
What is the meaning of crawing
to move along on hands and knees or with your body stretched out along a surface: The child crawled across the floor. Megan has just learned to crawl. The injured soldier crawled to safety. He had to crawl along a ledge and get in through a window.
What is crawling used for
Web crawling is commonly used to index pages for search engines. This enables search engines to provide relevant results for queries. Web crawling is also used to describe web scraping, pulling structured data from web pages, and web scraping has numerous applications.
What is crawling code
A web crawler is nothing but a few lines of code. This program or code works as an Internet bot. The task is to index the contents of a website on the internet. Now we know that most web pages are made and described using HTML structures and keywords.
What is crawling in machine learning
A Web crawler is an Internet bot that systematically browses the World Wide Web using the Internet Protocol Suite. Web Crawlers are useful in Machine Learning for collecting data that can be used for Modeling Processes such as training and prediction processing.
What is crawling data
What is Data crawling Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
What is called a crawler
A crawler is a computer program that visits websites and collects information when you do an internet search. [computing]
How does crawling work
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.

