
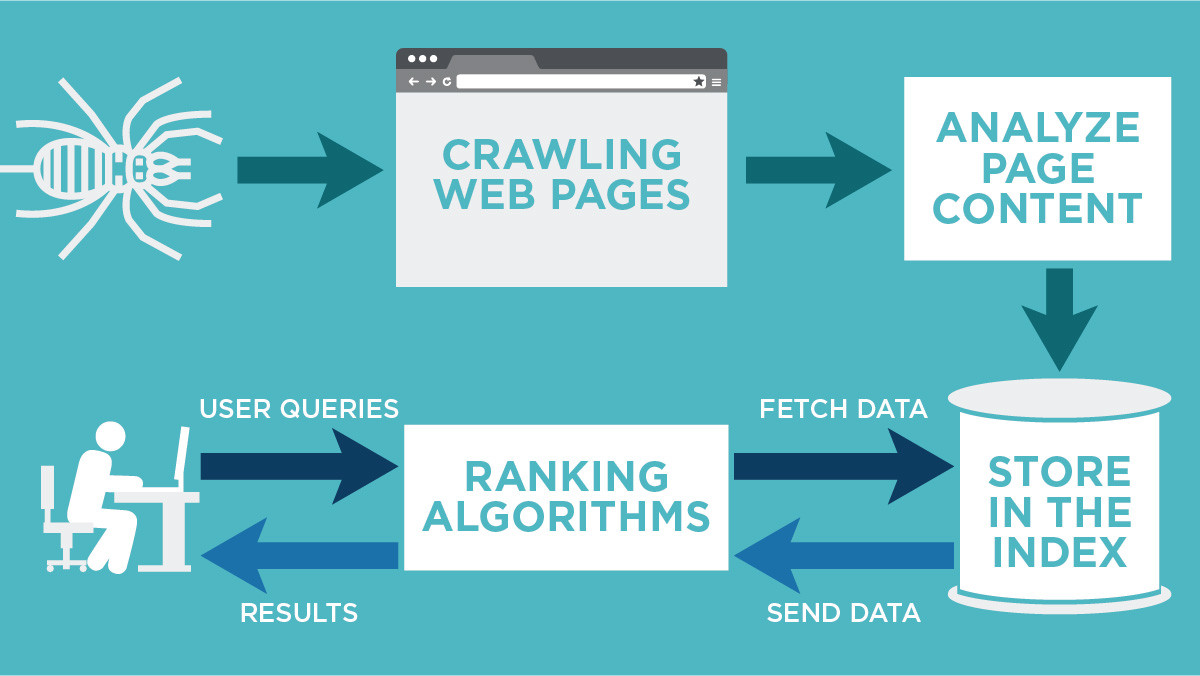
What is Google use to crawl a website
We use a huge set of computers to crawl billions of pages on the web. The program that does the fetching is called Googlebot (also known as a crawler, robot, bot, or spider). Googlebot uses an algorithmic process to determine which sites to crawl, how often, and how many pages to fetch from each site.
What crawler does Google use
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
What is the Google crawling process
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions. Learn more.
Does Google crawl all websites
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
What technology is used to crawl websites
Bots
Answer: Bots
The correct answer to which technology search engines use to crawl websites is bots. To help you understand why this is the correct answer, we have put together this quick guide on bots, search engines and website crawls.
Does Google crawl HTML
Google can only crawl your link if it's an <a> HTML element with an href attribute.
Is Google crawler based search engine
Google is a fully-automated search engine that uses software known as "web crawlers" that explore the web on a regular basis to find sites to add to our index.
How does SEO crawling work
Crawling is the discovery process in which search engines send out a team of robots (known as crawlers or spiders) to find new and updated content. Content can vary — it could be a webpage, an image, a video, a PDF, etc. — but regardless of the format, content is discovered by links.
Is it illegal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
How fast does Google crawl a site
Crawling can take anywhere from a few days to a few weeks. Be patient and monitor progress using either the Index Status report or the URL Inspection tool.
Which algorithm is used for web crawling
The first three algorithms given are some of the most commonly used algorithms for web crawlers. A* and Adaptive A* Search are the two new algorithms which have been designed to handle this traversal. Breadth First Search is the simplest form of crawling algorithm.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Does Google crawl with JavaScript
Google processes JavaScript web apps in three main phases: Crawling. Rendering. Indexing.
Does Googlebot crawl JavaScript
As Googlebot can crawl and render JavaScript content, there is no reason (such as preserving crawl budget) to block it from accessing any internal or external resources needed for rendering. Doing so would only prevent your content from being indexed correctly, and thus, poor SEO performance.
What technology do search engines use to crawl
Bots
Answer: Bots
The correct answer to which technology search engines use to crawl websites is bots. To help you understand why this is the correct answer, we have put together this quick guide on bots, search engines and website crawls.
How often do Google bots crawl a site
It's a common question in the SEO community and although crawl rates and index times can vary based on a number of different factors, the average crawl time can be anywhere from 3-days to 4-weeks. Google's algorithm is a program that uses over 200 factors to decide where websites rank amongst others in Search.
Is web scraping YouTube legal
Most data on YouTube is publicly accessible. Scraping public data from YouTube is legal as long as your scraping activities do not harm the scraped website's operations. It is important not to collect personally identifiable information (PII), and make sure that collected data is stored securely.
Is scraping TikTok legal
Scraping publicly available data on the web, including TikTok, is legal as long as it complies with applicable laws and regulations, such as data protection and privacy laws.
How does Google track if a place is busy
To determine popular times, wait times, and visit duration, Google uses aggregated and anonymized data from users who have opted in to Google Location History, which is off by default. Popular times, wait times, and visit duration are shown for the business if it gets enough visits from these users.
How many web crawlers does Google use
As for Google, there are more than 15 different types of crawlers, and the main Google crawler is called Googlebot. Googlebot performs both crawling and indexing, that's why we'll take a closer look at how it works.
What software program crawls the web
20 Best Web Crawling Tools & Software in 2023
| Best for | Price | |
|---|---|---|
| Apache Nutch | Writing scalable web crawlers | Free web crawling tool |
| Outwit Hub | Small projects | Free version available. Paid plan starts at $110/month |
| Cyotek WebCopy | Users with a tight budget | Free web crawling tool |
| WebSPHINX | Browsing offline | Free web crawling tool |
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
Which js does Google use
1. Angular. It is a framework written in TypeScript and developed by Google. It is an open-source web application framework used for developing single-page applications (SPA).
What JavaScript does Google use
V8 is the name of the JavaScript engine that powers Google Chrome. It's the thing that takes our JavaScript and executes it while browsing with Chrome. V8 provides the runtime environment in which JavaScript executes. The DOM and the other Web Platform APIs are provided by the browser.
Is Googlebot a web crawler
Googlebot is the generic name for Google's two types of web crawlers: Googlebot Desktop: a desktop crawler that simulates a user on desktop. Googlebot Smartphone: a mobile crawler that simulates a user on a mobile device.

