
What is the difference between Scrapy and crawl
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
What is crawler in Python
Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code. A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue.
What is crawling data
What is Data crawling Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
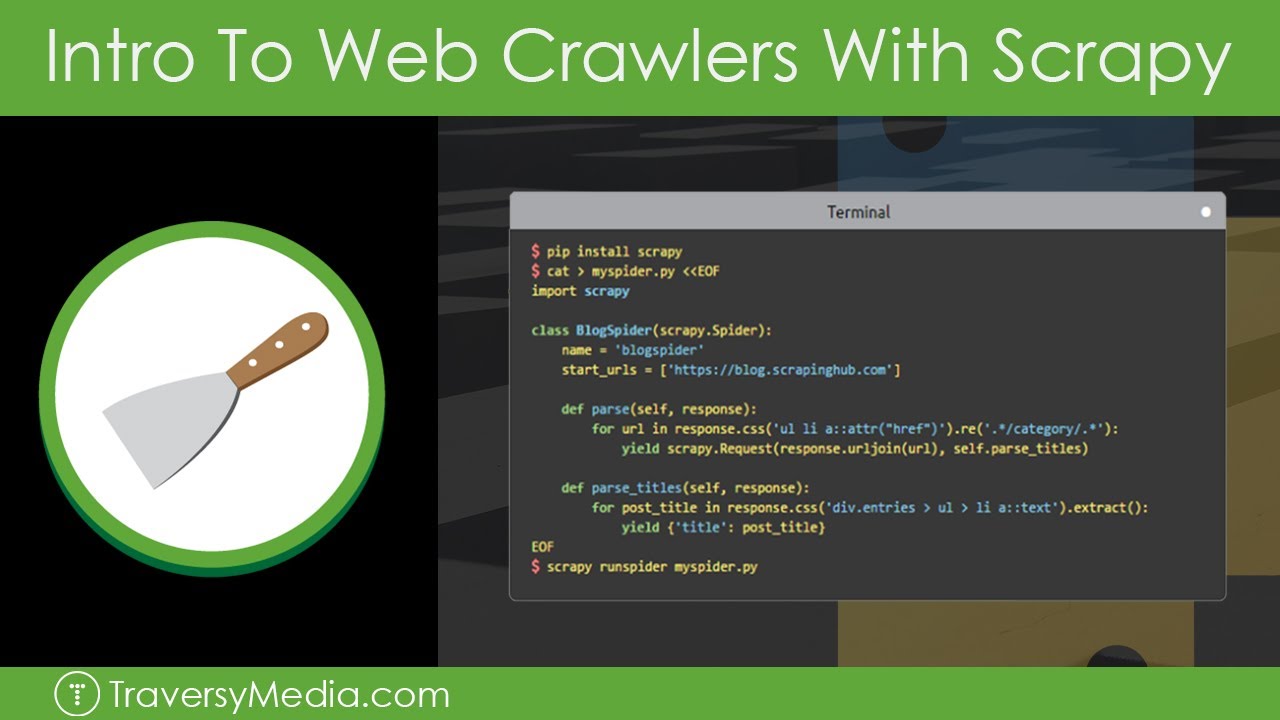
What is a spider in Scrapy
Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items).
How does crawling work
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
How do you crawl with Scrapy
Web scraping involves two steps: the first step is finding and downloading web pages, the second step is crawling through and extracting information from those web pages. There are a number of ways and libraries that can be used to build a web scraper from scratch in many programming languages.
What does a crawler do
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What is the use of crawler
Web search engines and some other websites use Web crawling or spidering software to update their web content or indices of other sites' web content. Web crawlers copy pages for processing by a search engine, which indexes the downloaded pages so that users can search more efficiently.
What is crawling used for
Web crawling is commonly used to index pages for search engines. This enables search engines to provide relevant results for queries. Web crawling is also used to describe web scraping, pulling structured data from web pages, and web scraping has numerous applications.
What do crawlers do
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What is the spider or crawler
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
What is spider crawler
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
What is the role of a crawler
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering).
Why is crawling important
These movements help build strength in their upper arms and shoulders. Crawling also develops an infant's upper and lower body coordination. We all have front-to-back and top-to-bottom invisible lines across our body, and crawling requires your brain to learn to coordinate movement across these lines.
What is crawling method
What is search engine crawling Crawling is the discovery process in which search engines send out a team of robots (known as crawlers or spiders) to find new and updated content. Content can vary — it could be a webpage, an image, a video, a PDF, etc. — but regardless of the format, content is discovered by links.
How does crawl work
A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
Why do we need web crawler
Web crawlers systematically browse webpages to learn what each page on the website is about, so this information can be indexed, updated and retrieved when a user makes a search query. Other websites use web crawling bots while updating their own web content.
What can you do with crawlers
Talk to neighbors. Play in the sidewalk leaves, scrunch leaves. Take a nature walk using the baby carrier, walk to forest area (for forest bathing). Play with balls outside, rolling balls to each other, practice throwing, crawl to chase balls, using tennis, soccer and, other various balls.
What does crawling work
Crawling engages your calves, quads, glutes, shoulder girdle, deep abdominal muscles, and muscles in your hips and feet. There are multiple variations on the basic form, too, Johnson said. Aside from crawling on your hands and knees, you can crawl on your hands and toes, or even facing up, in a crab crawl.
What is crawler mode
Crawl Control is designed for driving on difficult terrain at low speeds. It assists the driver by controlling acceleration and braking, allowing the driver to focus on steering.
What is the crawling process
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
What are the benefits of web crawlers
Why Web Crawlers Is ImportantExample of Web Crawlers.Benefits of Web Crawlers.Keeping Tabs on Competitors.Keeping Track With the Industry Trends.Leads Generation.Help You Get a Wind of What Is Said About You and Your Competitors on Social Media.Competitive Pricing.Target Listing.
What is the difference between a web crawler and a web scraper
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
How does a crawler work
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What is the difference between a crawler and a robot
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.

