
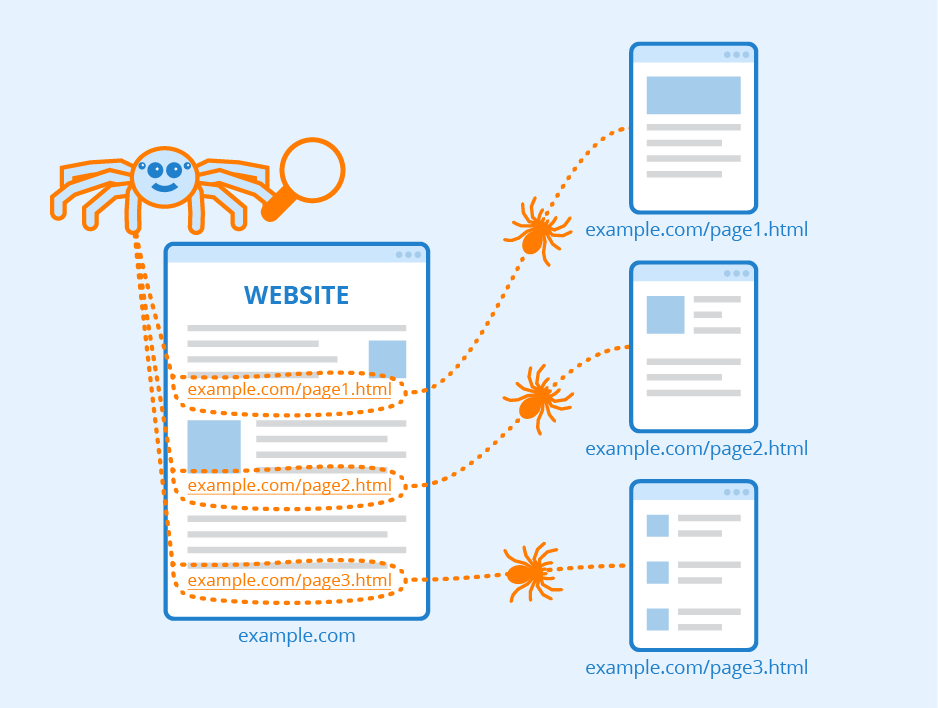
What is a search engine crawler
A crawler is a program used by search engines to collect data from the internet. When a crawler visits a website, it picks over the entire website's content (i.e. the text) and stores it in a databank. It also stores all the external and internal links to the website.
Is Google a crawler search engine
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.
What is a crawler in Google
Google uses crawlers and fetchers to perform actions for its products, either automatically or triggered by user request. "Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another.
What is crawl in Google search
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page.
Is Yahoo a crawler search engine
Yahoo provides effective web search features to users. It uses powerful algorithm and crawlers that helps it to list the webpages related to user query and keywords.
Is Bing a web crawler
Bing is a search engine owned by Microsoft and Bingbot is their standard crawler that handles most of the sites' crawling on a daily basis, for both desktop and mobile web! Bing operates five main crawlers: Bingbot. The standard crawler in charge of crawling and indexing sites.
What is the difference between a crawler and a search engine
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
Is Google a web crawler or web scraper
Google is most definitely a web crawler. They operate a web crawler with the name of Googlebot which searches for new websites, crawls them, and saves them in the massive search engine database. This is how Google powers its search engine and keeps it fresh with results from new websites.
Does Google crawl all websites
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
What is the difference between crawling and indexing Google
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages.
Is Bing a crawler based search engine
Crawler databases.
The search engine sends out many 'crawlers' which trawl the Web randomly, following links and indexing page content as they go. Some common crawlers are the GoogleBot and MSNBot which power Google and Bing.
Is Yahoo a web crawler
Search engines like Google, Bing, and Yahoo use crawlers to properly index downloaded pages so that users can find them faster and more efficiently when searching. Without web crawlers, there would be nothing to tell them that your website has new and fresh content.
What is the advantage of crawler
The main advantage of a crawler is that they can move on site and perform lifts with very little set-up, as the crane is stable on its tracks with no outriggers. In addition, a crawler crane is capable of traveling with a load.
Do all search engines use web crawlers
Most popular search engines have their own web crawlers that use a specific algorithm to gather information about webpages. Web crawler tools can be desktop- or cloud-based. Some examples of web crawlers used for search engine indexing include the following: Amazonbot is the Amazon web crawler.
Is it illegal to crawl a website
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
What does it mean when Google crawls a website
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
Is Yahoo a crawler based search engine
Starting on April 7, 2003, Yahoo! Search became its own web crawler-based search engine.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
What are the disadvantages of crawler
The main disadvantage of a crawler crane is that they are very heavy, and cannot easily be moved from one job site to the next without significant expense. Typically, a large crawler must be disassembled and moved by trucks, rail cars or ships to be transported to its next location.
Which crawler is best search engine
Google and Yahoo are examples of crawler search engines.
Are web crawlers illegal
United States: There are no federal laws against web scraping in the United States as long as the scraped data is publicly available and the scraping activity does not harm the website being scraped.
Is it legal to crawl YouTube
Most data on YouTube is publicly accessible. Scraping public data from YouTube is legal as long as your scraping activities do not harm the scraped website's operations. It is important not to collect personally identifiable information (PII), and make sure that collected data is stored securely.
Why do we crawl websites
Web crawlers systematically browse webpages to learn what each page on the website is about, so this information can be indexed, updated and retrieved when a user makes a search query. Other websites use web crawling bots while updating their own web content.
Why did Google stop crawling my site
Did you recently create the page or request indexing It can take time for Google to index your page; allow at least a week after submitting a sitemap or a submit to index request before assuming a problem. If your page or site change is recent, check back in a week to see if it is still missing.
How does Google crawling work
First, Google crawls the web to find new pages. Then, Google indexes these pages to understand what they are about and ranks them according to the retrieved data. Crawling and indexing are two different processes, still, they are both performed by a crawler.

