
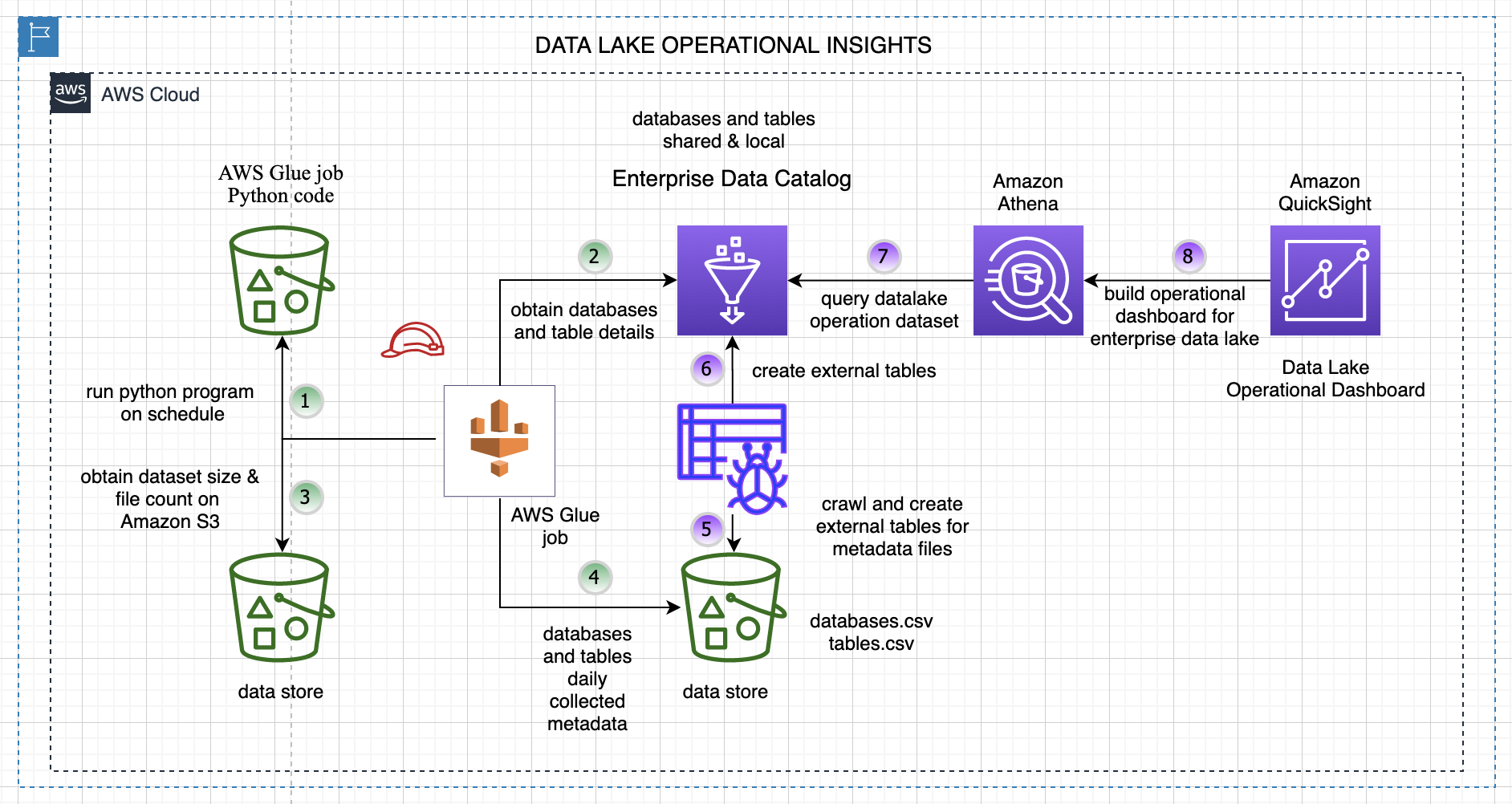
What is AWS data Catalogue
The AWS Glue Data Catalog is a centralized metadata repository for all your data assets across various data sources. It provides a unified interface to store and query information about data formats, schemas, and sources.
What is a glue data catalog object
With the AWS Glue Data Catalog, you can store up to a million objects for free. If you store more than a million objects, you will be charged $1.00 per 100,000 objects over a million, per month. An object in the AWS Glue Data Catalog is a table, table version, partition, partition indexes, or database.
What is the use of glue catalog
The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos. You can then use the metadata to query and transform that data in a consistent manner across a wide variety of applications.
What is the purpose of AWS Glue
AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development. Choose your preferred data integration engine in AWS Glue to support your users and workloads.
What is in a data Catalogue
A data catalog is a detailed inventory of all data assets in an organization, designed to help data professionals quickly find the most appropriate data for any analytical or business purpose.
What is the difference between data catalog and database
A database may have all the answers you need if you can spend the month required trawling through thousands of data points to find the few you need. A data catalog, on the other hand, will include a fully curated collection of datasets that have already been cleaned, vetted, and prepared for training and testing.
What does a data catalog do
Simply put, a data catalog is an organized inventory of data assets in the organization. It uses metadata to help organizations manage their data. It also helps data professionals collect, organize, access, and enrich metadata to support data discovery and governance.
What is the difference between data catalog and crawler
Information in the Data Catalog is stored as metadata tables, where each table specifies a single data store. Typically, you run a crawler to take inventory of the data in your data stores, but there are other ways to add metadata tables into your Data Catalog.
What is the purpose of data catalog
Simply put, a data catalog is an organized inventory of data assets in the organization. It uses metadata to help organizations manage their data. It also helps data professionals collect, organize, access, and enrich metadata to support data discovery and governance.
What is the difference between glue and Athena
A key difference between Glue and Athena is that Athena is primarily used as a query tool for analytics and Glue is more of a transformation and data movement tool. Creating tables for Glue to use in ETL jobs. The table must have a property added to them called a classification, which identifies the format of the data.
What is the difference between AWS Glue and data
A key difference between AWS Glue vs. Data Pipeline is that developers must rely on EC2 instances to execute tasks in a Data Pipeline job, which is not a requirement with Glue. AWS Data Pipeline manages the lifecycle of these EC2 instances, launching and terminating them when a job operation is complete.
What is data catalog example
Data catalogs should also provide users the ability to group assets in common sets. This can happen via tagging the data. For example, if you want to be able to see a report on all of your personally identifiable information (PII), you could tag all of your tables and fields that contain such data with “PII”.
Why is data catalog needed
A data catalog also allows you to establish links between business terms to establish a taxonomy. Beyond that, it can record relationships between terms and physical assets such as tables and columns. It also enables users to understand which business concepts are relevant to which technical artifacts.
What is a data catalog
Simply put, a data catalog is an organized inventory of data assets in the organization. It uses metadata to help organizations manage their data. It also helps data professionals collect, organize, access, and enrich metadata to support data discovery and governance.
What is the difference between data catalog and data warehouse
The main difference between a data catalog and a data warehouse is that most modern data platforms use data warehouses to store structured data and data catalogs to find, understand, trust, and use that data.
Why should I use a data catalog
Data catalogs help in Optimized data governance and business efficiency. Data catalogs ensure consistency in data quality. Data catalogs ensure regulatory compliance. Data catalogs help in Reducing spending and unnecessary costs.
What is data catalog vs data schema
From the SQL standard point of view : Catalogs are named collections of schemas in an SQL-environment. An SQL-environment contains zero or more catalogs. A catalog contains one or more schemas, but always contains a schema named INFORMATION_SCHEMA that contains the views and domains of the Information Schema.
What does a data catalog include
A data catalog is a detailed inventory of all data assets in an organization, designed to help data professionals quickly find the most appropriate data for any analytical or business purpose.
Can I use Athena without Glue
Athena cannot work without Glue unless you upgrade to the AWS Glue Data Catalog. Athena queries will fail if you upgrade to the AWS Glue Data Catalog without updating a user's customer-managed or inline IAM policies, as the user won't be permitted to take actions in AWS Glue.
Do you need Glue for Athena
Athena uses the AWS Glue Data Catalog to store and retrieve table metadata for the Amazon S3 data in your Amazon Web Services account. The table metadata lets the Athena query engine know how to find, read, and process the data that you want to query.
What is the difference between AWS Glue data Catalog and Athena
A key difference between Glue and Athena is that Athena is primarily used as a query tool for analytics and Glue is more of a transformation and data movement tool. Creating tables for Glue to use in ETL jobs. The table must have a property added to them called a classification, which identifies the format of the data.
What is AWS Glue data Catalog table
A table in the AWS Glue Data Catalog is the metadata definition that represents the data in a data store. You create tables when you run a crawler, or you can create a table manually in the AWS Glue console. The Tables list in the AWS Glue console displays values of your table's metadata.
Who needs a data catalog
Lyons and Burnham pointed to other scenarios indicating that a company might benefit from a data catalog: if your data analysts and data scientists are spending a long time looking for data rather than analyzing it; if much of your workforce is getting close to retirement age (or you have high employee turnover) and …
What is cloud data catalog
Data Catalog is a fully managed and scalable metadata management service that empowers organizations to quickly discover, understand, and manage all of their data. In this quest you will start small by learning how to search and tag data assets and metadata with Data Catalog.
What is the purpose of the data catalog
A data catalog is a detailed inventory of all data assets in an organization, designed to help data professionals quickly find the most appropriate data for any analytical or business purpose.

