
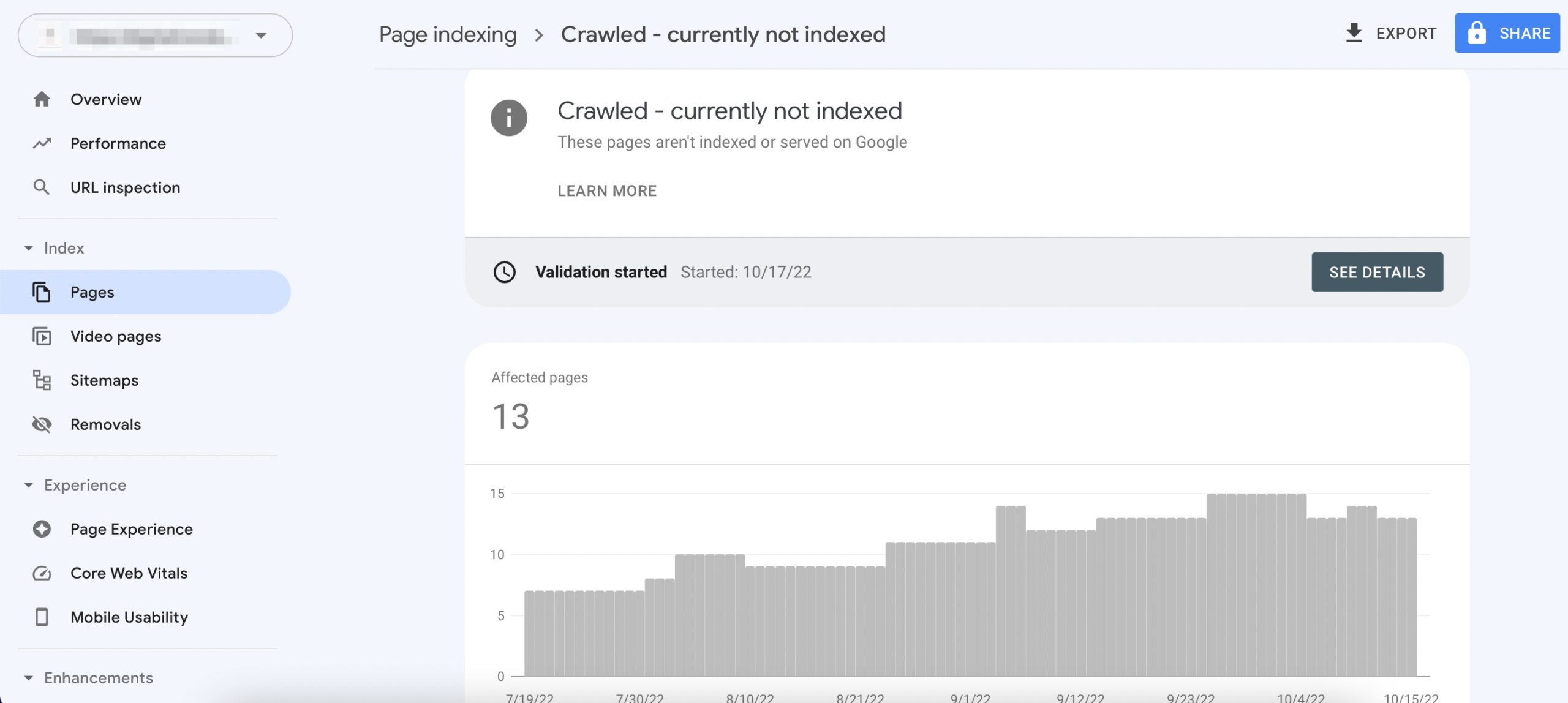
What does crawled but not indexed mean
If you've submitted a URL to Google Search Console and got the message Crawled – Currently Not Indexed, it means Google has crawled the page but chose to not index it. As a result, the URL won't appear in search results for the time being.
Why is a page crawled but not indexed
Crawled – currently not indexed means Google has crawled your page but has not indexed it yet. As we already know, Google does not index all the URLs we submit, and finding a certain number of URLs under this status is completely normal.
What does it mean to not be indexed
The Discovered – currently not indexed status means that Google knows about these URLs, but they haven't crawled (and therefore indexed) them yet. If you're running a small website (below 10.000 pages) with good quality content, this URL state is will automatically resolve after Google's crawled the URLs.
How does Google crawl and index
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
What is crawled vs indexed
Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.
Does no index affect Google ads
Being in Google's search index (or not) makes no difference to Analytics, Google Ads tracking or running Google Ads.
Why is Google removing indexed pages
Google may temporarily or permanently remove sites from its index and search results if it believes it is obligated to do so by law, if the sites do not meet Google's quality guidelines, or for other reasons, such as if the sites detract from users' ability to locate relevant information.
What is indexed vs non-indexed
Because indexed searches are performed using the search engine, they support features such as root word search, fuzzy search, search context hits, and relevance ranking. Non-indexed searches support case and accent sensitivity settings, and require the use of wildcards for non-exact matches.
What does indexed vs non-indexed mean
Indexation of a journal is considered a reflection of its quality. Indexed journals are considered to be of higher scientific quality as compared to non-indexed journals.
What is the difference between crawled and indexed
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.
What is crawling vs indexing in SEO
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
What is crawling vs indexing vs ranking
Indexing – Once a page is crawled, search engines add it to their database. For Google, crawled pages are added to the Google Index. Ranking- After indexing, search engines rank pages based on various factors. In fact, Google weighs pages against its 200+ ranking factors before ranking them.
Is no index bad for SEO
Making low-quality pages non-indexable is one of SEO best practices for optimizing your indexing strategy – and using the noindex meta tag is one of the most optimal ways to keep a page out of Google's index.
Does no index affect SEO
Having noindex URLs normally does not affect how Google crawls the rest of your website—unless you have a large number of noindexed pages that need to be crawled in order to reach a small number of indexable pages.
How do I fix crawled but not indexed
Solution: Create a temporary sitemap. xml.Export all of the URLs from the “Crawled — currently not indexed” report.Match them up in Excel with redirects that have been previously set up.Find all of the redirects that have a destination URL in the “Crawled — currently not indexed” bucket.Create a static sitemap.
Why is my page discovered but not indexed by Google
Google may have tried to crawl the URL but the site was overloaded. If that's the case then Google will reschedule the crawl for a later date. Another reason for the 'Discovered – Currently not indexed' message could be because the website doesn't meet a certain threshold for quality, in Google's view.
What is the difference between crawling indexing and ranking
In a nutshell, this process involves the following steps: Crawling – Following links to discover the most important pages on the web. Indexing – Storing information about all the retrieved pages for later retrieval. Ranking – Determining what each page is about, and how it should rank for relevant queries.
Is crawling the same as indexing
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.
What’s the difference between crawling and indexing
Crawling: Scour the Internet for content, looking over the code/content for each URL they find. Indexing: Store and organize the content found during the crawling process. Once a page is in the index, it's in the running to be displayed as a result to relevant queries.
Is crawling and indexing the same
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.
What happens first crawling or indexing
Crawling is the very first step in the process. It is followed by indexing, ranking (pages going through various ranking algorithms) and finally, serving the search results.
Why is 0 indexing better
As you can see, it is a lot easier to 0-based array indexing because you can calculate the nth term a lot easier without having to subtract 1 from n before multiplying the common difference. That's exactly 1 scenario where 0-based indexing might come in handy.
Is it bad to have non indexed pages
It's fine for a URL not to be indexed for the right reasons—for example, an expected robots. txt rule on your site, a noindex tag on the page, a duplicate URL, or a 404 for a page that you've removed and have no replacement for.
What happen if we do not have indexing
Indexing is the way to get an unordered table into an order that will maximize the query's efficiency while searching. When a table is unindexed, the order of the rows will likely not be discernible by the query as optimized in any way, and your query will therefore have to search through the rows linearly.
What is indexed vs crawled content
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.

