
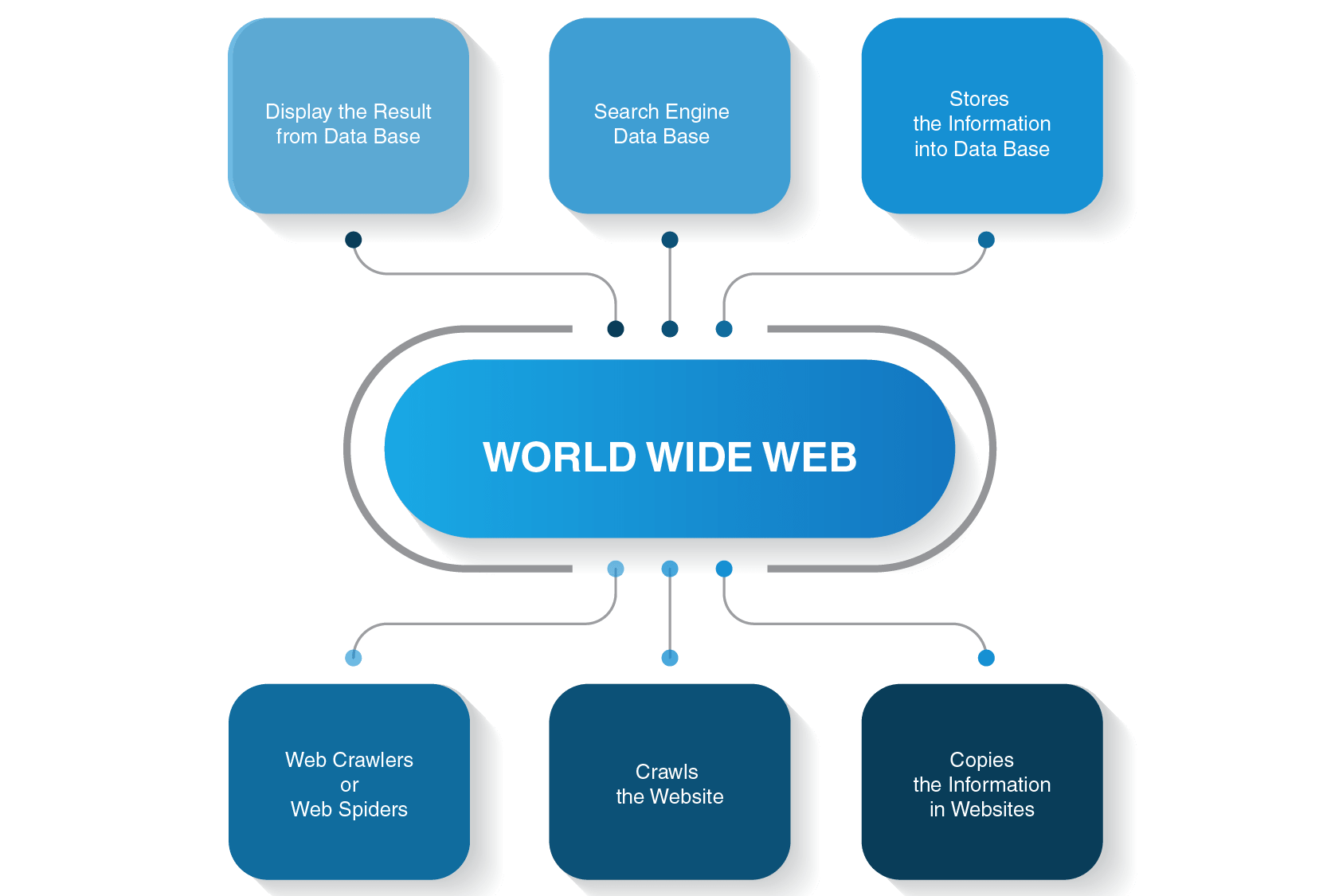
How does the crawler work
While on a webpage, the crawler stores the copy and descriptive data called meta tags, and then indexes it for the search engine to scan for keywords. This process then decides if the page will show up in search results for a query, and if so, returns a list of indexed webpages in order of importance.
How does a crawler work in SEO
A crawler is a program used by search engines to collect data from the internet. When a crawler visits a website, it picks over the entire website's content (i.e. the text) and stores it in a databank. It also stores all the external and internal links to the website.
What is a crawler system
What is Web Crawler Web crawler (also known as a spider) is a system for downloading, storing, and analyzing web pages. It performs the task of organizing web pages that allow users to easily find information. This is done by collecting a few web pages and following links to gather new content.
Why do we need crawler
With Crawlers, you can quickly and easily scan your data sources, such as Amazon S3 buckets or relational databases, to create metadata tables that capture the schema and statistics of your data.
How does crawler glue work
Glue Crawler groups the data into tables or partitions based on data classification. If the crawler is getting metadata from S3, it will look for folder-based partitions so that the data can be grouped aptly.
What is crawler type SEO
SEO crawlers are tools that crawl pages of a website, much like search engine crawlers do, in order to gain valuable SEO information. A good SEO crawler will inevitably make technical SEO work much easier and less time-consuming.
Why are web crawlers important for SEO
The crawler records your site's copy and meta tags to understand the keywords and the purpose of your site. The crawlers index the page based on the searchable terms it finds. Search engines use this index to pull up a list of relevant webpages when you enter a search term.
What is crawl process
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
What is crawler architecture
Web Crawler Architecture
The front end is the user interface where the user inputs the initial URL and specifies what information they want to extract. The back end is responsible for performing the actual web crawling process and consists of multiple modules such as a URL scheduler, a downloader, and a parser.
What is the difference between crawler and robot
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
What are the advantages of web crawler
Web Crawlers allow you to come up with a target list of companies or individual contacts for all kinds of purposes. With Crawler, you can be accessible to information like phone numbers, address, email address, and all. It can also set up a list of targeted websites providing relevant company listings.
Do I need a crawler in glue
Before you start troubleshooting, consider whether or not you need to run a crawler. Unless you need to create a table in the AWS Glue Data Catalog and use the table in an extract, transform, and load (ETL) job or a downstream service, such as Amazon Athena, you don't need to run a crawler.
Why is crawler used
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What is the difference between Google bot and crawler
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
What is the advantage of crawler
The main advantage of a crawler is that they can move on site and perform lifts with very little set-up, as the crane is stable on its tracks with no outriggers. In addition, a crawler crane is capable of traveling with a load.
How do you crawl step by step
For the most basic crawl, follow the steps below:Get on your hands and knees.Make sure your hips align with your knees and your hands are shoulder-width apart.Move your right hand and left knee forward and then vice versa.Brace your core as you move forward.
What happens in crawling
She'll use her legs to pull herself forward as she slides around on her well-cushioned backside. The classic crawl. This one's exactly what you probably picture when you think of crawling — from her tummy, baby pushes up onto her hands and knees and moves by alternating the opposite leg and arm forward.
What is the role of crawler in data mining
In the area of data mining, a crawler may collect publicly available e-mail or postal addresses of companies. Web analysis tools use crawlers or spiders to collect data for page views, or incoming or outbound links. Crawlers serve to provide information hubs with data, for example, news sites.
What is crawler database
What is the meaning of data crawling on the Internet A web crawler (or a spider tool) is an automated script that helps you browse and gather publicly available data on the web. Many websites use data crawling to get up-to-date data.
How is crawling different from screen scraping
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web.
What is also called crawler robot or bot
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering).
What are the disadvantages of crawler
The main disadvantage of a crawler crane is that they are very heavy, and cannot easily be moved from one job site to the next without significant expense. Typically, a large crawler must be disassembled and moved by trucks, rail cars or ships to be transported to its next location.
Is Google a web crawler
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.
What is crawler in cyber security
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering).
What is the best way to crawl
And then bring that left knee up I reach with my arm. I bring the leg behind. Me. Quite simple right come on back. Now this is very very easy.

