
What is Python crawling
Web crawling is a powerful technique to collect data from the web by finding all the URLs for one or multiple domains. Python has several popular web crawling libraries and frameworks. In this article, we will first introduce different crawling strategies and use cases.
What is crawling in programming
Crawling refers to following the links on a page to new pages, and continuing to find and follow links on new pages to other new pages. A web crawler is a software program that follows all the links on a page, leading to new pages, and continues that process until it has no more new links or pages to crawl.
What is data crawling
What is Data crawling Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
What is the difference between scraping and crawling
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web.
What is a crawl bot
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
How to make a crawler in Python
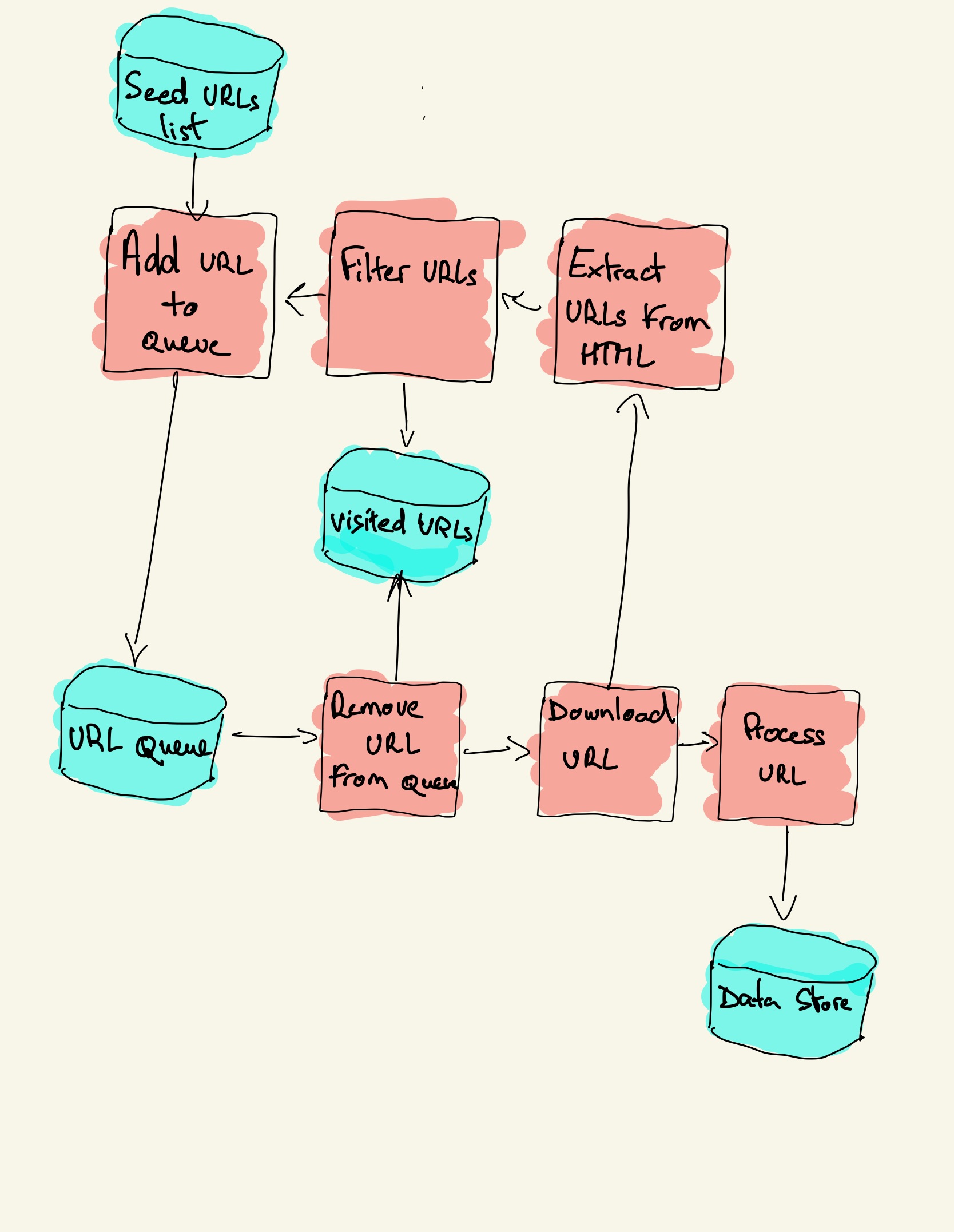
Building a Web Crawler using Pythona name for identifying the spider or the crawler, “Wikipedia” in the above example.a start_urls variable containing a list of URLs to begin crawling from.a parse() method which will be used to process the webpage to extract the relevant and necessary content.
What is crawling in machine learning
A Web crawler is an Internet bot that systematically browses the World Wide Web using the Internet Protocol Suite. Web Crawlers are useful in Machine Learning for collecting data that can be used for Modeling Processes such as training and prediction processing.
How do you make a crawler in Python
The basic workflow of a general web crawler is as follows:Get the initial URL.While crawling the web page, we need to fetch the HTML content of the page, then parse it to get the URLs of all the pages linked to this page.Put these URLs into a queue;
What is API crawling
Spider a site for links and processes them with Extract API. Crawl works hand-in-hand with Extract API (either automatic or custom). It quickly spiders a site for appropriate links and hands these links to an Extract API for processing.
What is crawling good for
Research has shown that baby crawling increases hand-eye coordination, gross and fine motor skills (large and refined movements), balance, and overall strength.
Why are bots crawling my site
While bots can serve useful purposes, such as indexing your site for search engines, many bots are designed to scrape your content, use your resources, or even harm your site.
How does a web crawler work
A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How do you crawl a page
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
Why is crawling good
Research has shown that baby crawling increases hand-eye coordination, gross and fine motor skills (large and refined movements), balance, and overall strength.
How to code a data crawler
Here are the basic steps to build a crawler:Step 1: Add one or several URLs to be visited.Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread.Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
Why is crawler used
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What is the difference between crawler and bot
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
Why is crawling longer better
Crawling Improves Their Physical Capabilities
This help to improve their: Gross motor skills (the larger movements they make) Fine motor skills. Coordination.
When should you crawl
between 7 and 10 months
When should I expect my baby to crawl Many babies will crawl between 7 and 10 months of age [1]. Of course, baby development is on a spectrum, and some babies may be crawling at 6 months or may start to crawl later than 10 months, and some may skip crawling altogether.
How do I stop bot crawling
How to Stop Bots from Crawling Your SiteUse Robots.txt. The robots.txt file is a simple way to tell search engines and other bots which pages on your site should not be crawled.Implement CAPTCHAs.Use HTTP Authentication.Block IP Addresses.Use Referrer Spam Blockers.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Is data crawling ethical
Crawlers are involved in illegal activities as they make copies of copyrighted material without the owner's permission. Copyright infringement is one of the most important legal issues for search engines that need to be addressed upon.
How do you crawl a page in Python
Put these URLs into a queue; Loop through the queue, read the URLs from the queue one by one, for each URL, crawl the corresponding web page, then repeat the above crawling process; Check whether the stop condition is met. If the stop condition is not set, the crawler will keep crawling until it cannot get a new URL.
What is crawling a website mean
Web crawlers systematically browse webpages to learn what each page on the website is about, so this information can be indexed, updated and retrieved when a user makes a search query. Other websites use web crawling bots while updating their own web content.

