
What does crawler mean in data
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
What is crawler and how it works
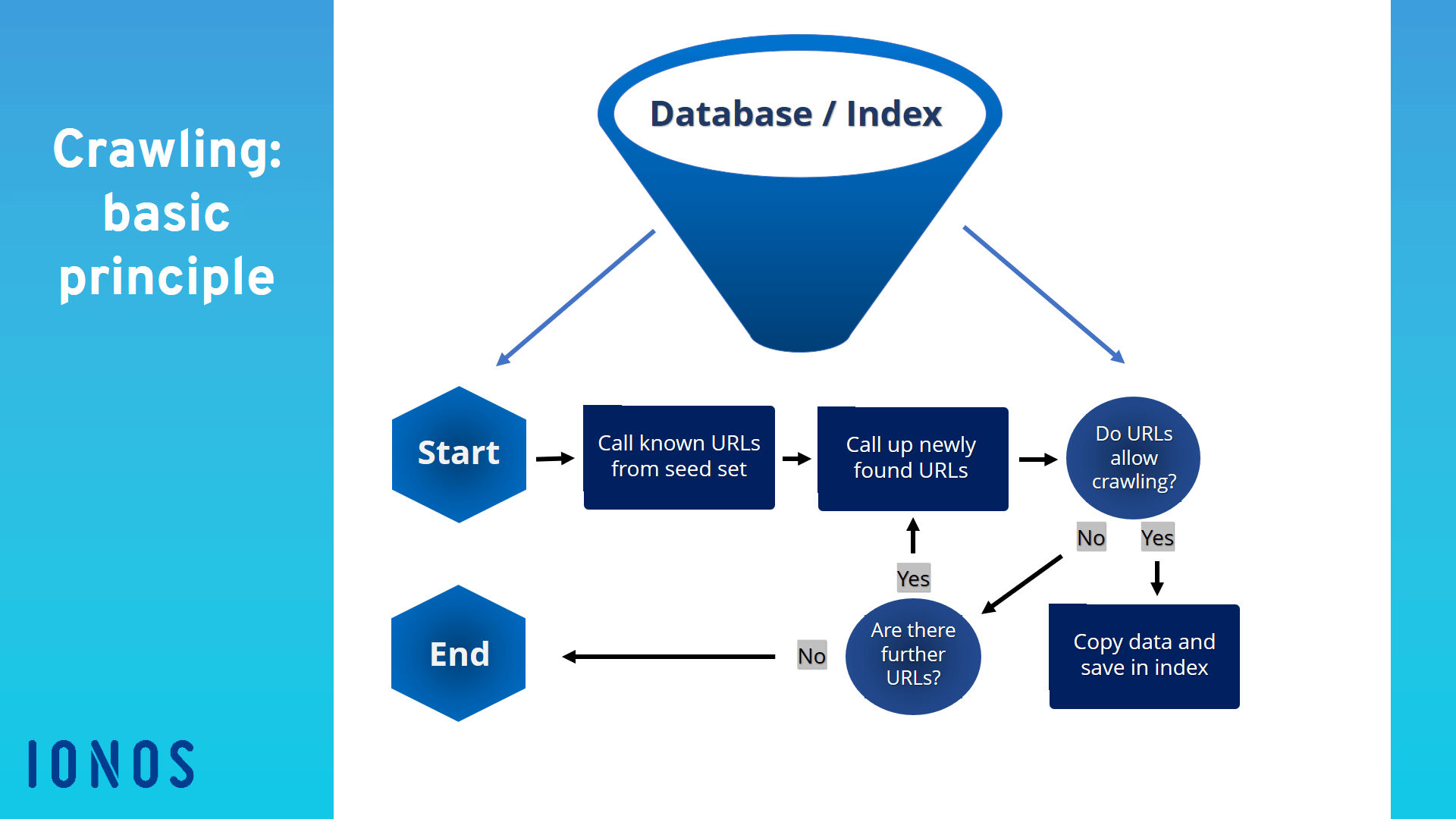
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
How does data crawling work
How do web crawlers work A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
What is data scraping and crawling
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How to do data crawling
Here are the basic steps to build a crawler:Step 1: Add one or several URLs to be visited.Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread.Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
Why do we need crawler
With Crawlers, you can quickly and easily scan your data sources, such as Amazon S3 buckets or relational databases, to create metadata tables that capture the schema and statistics of your data.
What is the difference between crawler and scraping
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
Is data scraping bad
“While web scraping has valid business purposes, such as research, analysis, and news distribution, it can also be used for malicious purposes, such as sensitive data mining.”
Is data crawling ethical
Crawlers are involved in illegal activities as they make copies of copyrighted material without the owner's permission. Copyright infringement is one of the most important legal issues for search engines that need to be addressed upon.
What is data crawling in Python
Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code. A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue.
What is the difference between crawler and robot
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
What is the difference between data catalog and crawler
Information in the Data Catalog is stored as metadata tables, where each table specifies a single data store. Typically, you run a crawler to take inventory of the data in your data stores, but there are other ways to add metadata tables into your Data Catalog.
Is Google a web crawler or web scraper
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.
What is the advantage of crawler
The main advantage of a crawler is that they can move on site and perform lifts with very little set-up, as the crane is stable on its tracks with no outriggers. In addition, a crawler crane is capable of traveling with a load.
Do hackers use web scraping
A scraping bot can gather user data from social media sites. Then, by scraping sites that contain addresses and other personal information and correlating the results, a hacker could engage in identity crimes like submitting fraudulent credit card applications.
Is it legal to scrape emails
Challenge. Check rules/regulations: Scraping publicly available data on the web is legal but you must consider data security and user privacy.
How to crawl data from website using Python
To extract data using web scraping with python, you need to follow these basic steps:Find the URL that you want to scrape.Inspecting the Page.Find the data you want to extract.Write the code.Run the code and extract the data.Store the data in the required format.
Why is CNC not a robot
Workspace — The workspace of a CNC machine can usually be defined as a small cube. Robots, by contrast, usually have a large, spherical workspace. Programming — CNC machines are programmed using G-Code. These days, this is most often generated by a CAM software, not coded by hand.
What is the difference between robot and Cobot
The main differences between robots and cobots
While a robot performs a task without human control, a cobot performs tasks in collaboration with human workers.
What is classifier vs crawler
Classifier types include defining schemas based on grok patterns, XML tags, and JSON paths. If you change a classifier definition, any data that was previously crawled using the classifier is not reclassified. A crawler keeps track of previously crawled data.
Is it okay to scrape Google
Google's terms of service restrict web scraping, but there're some exceptions for certain types of data and use cases. That being said, it's always a good idea to be cautious and respectful of website policies and terms of service when scraping data.
What are the disadvantages of crawler
The main disadvantage of a crawler crane is that they are very heavy, and cannot easily be moved from one job site to the next without significant expense. Typically, a large crawler must be disassembled and moved by trucks, rail cars or ships to be transported to its next location.
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
Do I need VPN for web scraping
Most web scrapers need proxies to scrape without being blocked. However, proxies can be expensive and out of reach for many small web scrapers. One alternative to proxies is to use personal VPN services as proxy clients.

