
What is Google crawler in SEO
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
What is Google crawling
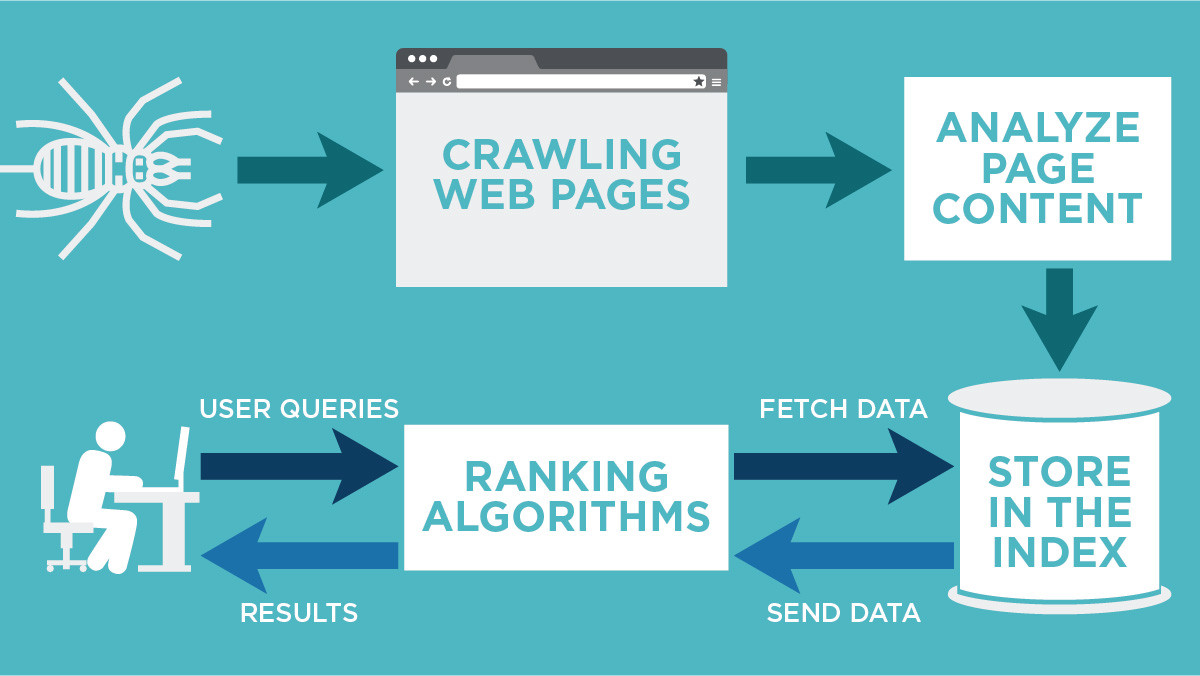
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
Why is crawling important in SEO
Crawling is crucial for SEO because it allows search engines to understand the content on your website and rank it based on relevance and quality. If your website is not crawled, it will not appear in search engine results pages (SERPs), which means you'll miss out on valuable organic traffic.
What is the difference between crawling and indexing in Google
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages.
What is crawling vs indexing in SEO
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
What is the difference between a crawler and a search engine
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
How does Google crawl a website
Most of our Search index is built through the work of software known as crawlers. These automatically visit publicly accessible web pages and follow links on those pages, much like you would if you were browsing content on the web.
How do I know if Google is crawling my website
For a definitive test of whether your URL is appearing, search for the page URL on Google. The "Last crawl" date in the Page availability section shows the date when the page used to generate this information was crawled.
What is crawl budget and why does it matter for SEO
Taking crawl capacity and crawl demand together, Google defines a site's crawl budget as the set of URLs that Googlebot can and wants to crawl. Even if the crawl capacity limit isn't reached, if crawl demand is low, Googlebot will crawl your site less.
What is crawling vs indexing vs ranking
Indexing – Once a page is crawled, search engines add it to their database. For Google, crawled pages are added to the Google Index. Ranking- After indexing, search engines rank pages based on various factors. In fact, Google weighs pages against its 200+ ranking factors before ranking them.
Why does Google crawl but not index
This product listing page was flagged as “Crawled — Currently Not Indexed”. This may be due to very thin content on the page. This page is likely either too thin for Google to think it's useful or there is so little content that Google considers it to be a duplicate of another page.
What is the difference between crawling indexing and ranking
In a nutshell, this process involves the following steps: Crawling – Following links to discover the most important pages on the web. Indexing – Storing information about all the retrieved pages for later retrieval. Ranking – Determining what each page is about, and how it should rank for relevant queries.
What is the advantage of crawler
The main advantage of a crawler is that they can move on site and perform lifts with very little set-up, as the crane is stable on its tracks with no outriggers. In addition, a crawler crane is capable of traveling with a load.
Is Google crawler based search engine
Google is a fully-automated search engine that uses software known as "web crawlers" that explore the web on a regular basis to find sites to add to our index.
What is an example of crawling a website
Some examples of web crawlers used for search engine indexing include the following: Amazonbot is the Amazon web crawler. Bingbot is Microsoft's search engine crawler for Bing. DuckDuckBot is the crawler for the search engine DuckDuckGo.
How do I make Google crawl my site
Use the URL Inspection tool (just a few URLs)
To request a crawl of individual URLs, use the URL Inspection tool. You must be an owner or full user of the Search Console property to be able to request indexing in the URL Inspection tool.
How often does Google crawl for SEO
It's a common question in the SEO community and although crawl rates and index times can vary based on a number of different factors, the average crawl time can be anywhere from 3-days to 4-weeks.
What is crawling and indexing in SEO
Crawling: Scour the Internet for content, looking over the code/content for each URL they find. Indexing: Store and organize the content found during the crawling process. Once a page is in the index, it's in the running to be displayed as a result to relevant queries.
Is crawling a ranking factor
The ranking stage includes most of the analysis performed by Google's algorithms. To be considered a ranking factor, something needs to be given weight during the ranking stage. While crawling is required for ranking once met, this prerequisite is not weighted during ranking.
What is the difference between crawl and index
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
How do you solve crawled but not indexed
How to fix “Crawled ‐ currently not indexed”Provide high-quality content.Monitor your index coverage.Design a sound website structure.Limit your duplicate content.
What is the relationship between crawlers and SEO
The Importance of a Crawler
The organic search process can't be complete unless a crawler has access to your site. Remember your goal as an SEO is to have your web pages rank on a search engine's results page. To be on the results page — in any rank position — a crawler needs to visit your site.
What are the disadvantages of crawler
The main disadvantage of a crawler crane is that they are very heavy, and cannot easily be moved from one job site to the next without significant expense. Typically, a large crawler must be disassembled and moved by trucks, rail cars or ships to be transported to its next location.
What is an example of crawler
For example, Google has its main crawler, Googlebot, which encompasses mobile and desktop crawling. But there are also several additional bots for Google, like Googlebot Images, Googlebot Videos, Googlebot News, and AdsBot. Here are a handful of other web crawlers you may come across: DuckDuckBot for DuckDuckGo.
How do you know if a website can be crawled
If the URL is not within a Search Console property that you ownOpen the Rich Results test.Enter the URL of the page or image to test and click Test URL.In the results, expand the "Crawl" section.You should see the following results: Crawl allowed – Should be "Yes".

