
What does crawling data mean
What is Data crawling Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
What is Spidering data
Web search engines and some other websites use Web crawling or spidering software to update their web content or indices of other sites' web content. Web crawlers copy pages for processing by a search engine, which indexes the downloaded pages so that users can search more efficiently.
How does data crawling work
How do web crawlers work A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
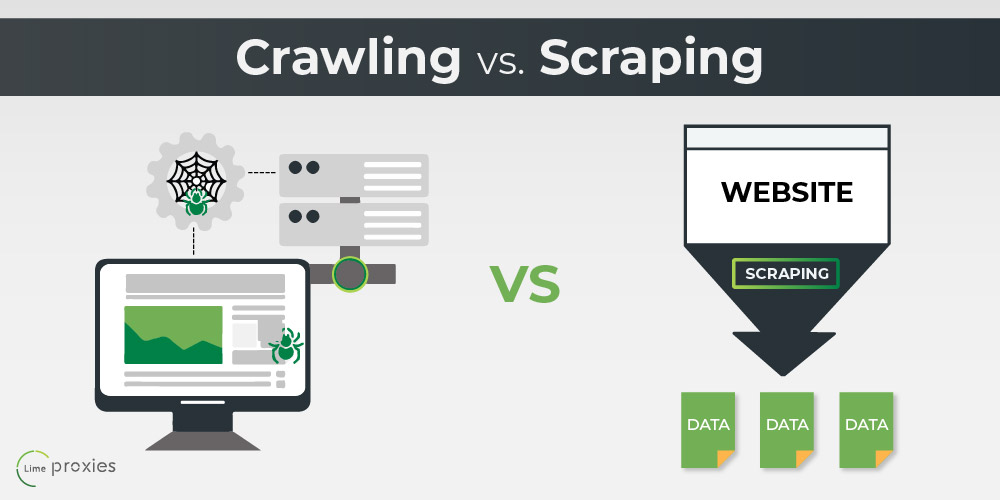
What is the difference between crawling and scraping data
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
What is crawling in machine learning
A Web crawler is an Internet bot that systematically browses the World Wide Web using the Internet Protocol Suite. Web Crawlers are useful in Machine Learning for collecting data that can be used for Modeling Processes such as training and prediction processing.
What is common crawl dataset
The Common Crawl corpus contains petabytes of data collected over 12 years of web crawling. The corpus contains raw web page data, metadata extracts and text extracts. Common Crawl data is stored on Amazon Web Services' Public Data Sets and on multiple academic cloud platforms across the world.
How do you do data crawling
The six steps to crawling a website include:Understanding the domain structure.Configuring the URL sources.Running a test crawl.Adding crawl restrictions.Testing your changes.Running your crawl.
What is the difference between crawling and Spidering
Spider- A browser like program that downloads web pages. Crawler- A program that automatically follows all of the links on each web page.
How to do data crawling
Here are the basic steps to build a crawler:Step 1: Add one or several URLs to be visited.Step 2: Pop a link from the URLs to be visited and add it to the Visited URLs thread.Step 3: Fetch the page's content and scrape the data you're interested in with the ScrapingBot API.
What is crawler and how it works
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What is data crawling in Python
Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code. A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue.
Does Google use Common Crawl
Google's version of the Common Crawl is called the Colossal Clean Crawled Corpus, or C4 for short.
How big is the Common Crawl data set
The new dataset is over 266TB in size containing approximately 3.6 billion webpages. The new data is located in the commoncrawl bucket at /crawl-data/CC-MAIN-2014-23/. To assist with exploring and using the dataset, we've provided gzipped files that list: all segments (CC-MAIN-2014-23/segment.
What is Common Crawl dataset
The Common Crawl corpus contains petabytes of data collected over 12 years of web crawling. The corpus contains raw web page data, metadata extracts and text extracts. Common Crawl data is stored on Amazon Web Services' Public Data Sets and on multiple academic cloud platforms across the world.
What does crawling mean in Google
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
What is crawling vs indexing
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
What is an example of a crawler
All search engines need to have crawlers, some examples are: Amazonbot is an Amazon web crawler for web content identification and backlink discovery. Baiduspider for Baidu. Bingbot for Bing search engine by Microsoft.
Why do we need crawler
With Crawlers, you can quickly and easily scan your data sources, such as Amazon S3 buckets or relational databases, to create metadata tables that capture the schema and statistics of your data.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How do you crawl data from a website
There are roughly 5 steps as below:Inspect the website HTML that you want to crawl.Access URL of the website using code and download all the HTML contents on the page.Format the downloaded content into a readable format.Extract out useful information and save it into a structured format.
How do I know if Google is crawling my website
For a definitive test of whether your URL is appearing, search for the page URL on Google. The "Last crawl" date in the Page availability section shows the date when the page used to generate this information was crawled.
What is an example website for crawling
Some examples of web crawlers used for search engine indexing include the following: Amazonbot is the Amazon web crawler. Bingbot is Microsoft's search engine crawler for Bing. DuckDuckBot is the crawler for the search engine DuckDuckGo.
What is in the Common Crawl dataset
The Common Crawl corpus contains petabytes of data collected over 12 years of web crawling. The corpus contains raw web page data, metadata extracts and text extracts. Common Crawl data is stored on Amazon Web Services' Public Data Sets and on multiple academic cloud platforms across the world.
How do I get data from Common Crawl
Data Location
For all crawls, it is stored in Amazon S3 as WARC file format and also contains metadata (WAT) and text data (WET) extracts. It provides file path for WAT and WET extract separately. You can access file from s3 by replacing s3://commoncrawl by https://commoncrawl.s3.amazonaws.com/ on each line.
What does crawling mean in SEO
What Is Crawling In SEO. In the context of SEO, crawling is the process in which search engine bots (also known as web crawlers or spiders) systematically discover content on a website. This may be text, images, videos, or other file types that are accessible to bots.

