
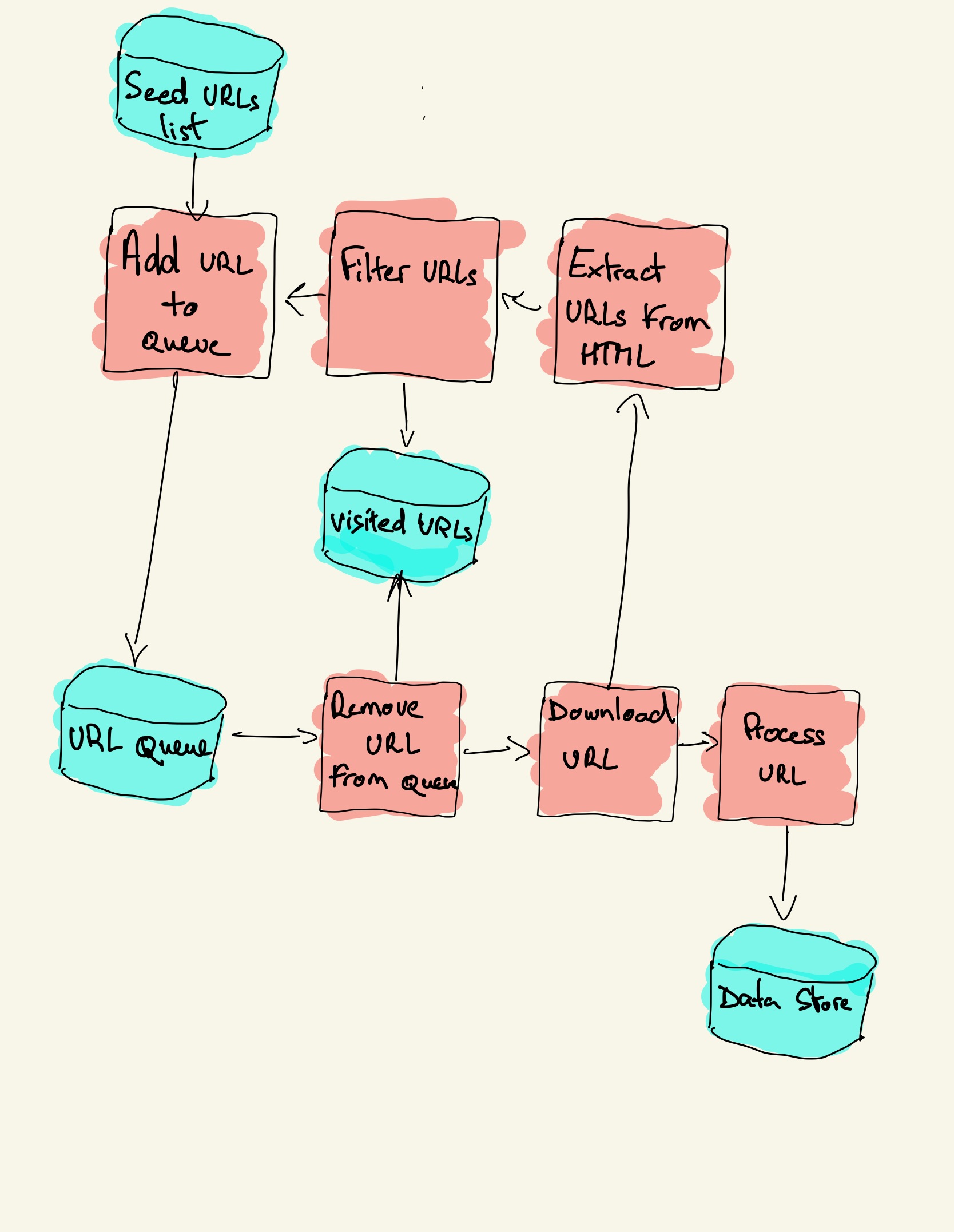
What is Python crawler
Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code. A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue.
What is crawling data
What is Data crawling Data crawling is a method which involves data mining from different web sources. Data crawling is very similar to what the major search engines do. In simple terms, data crawling is a method for finding web links and obtaining information from them.
What is the difference between scraping and crawling
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web.
How to use web crawler in Python
The basic workflow of a general web crawler is as follows:Get the initial URL.While crawling the web page, we need to fetch the HTML content of the page, then parse it to get the URLs of all the pages linked to this page.Put these URLs into a queue;
Why is crawler used
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What is the difference between crawler and bot
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
What is crawling used for
Web crawling is commonly used to index pages for search engines. This enables search engines to provide relevant results for queries. Web crawling is also used to describe web scraping, pulling structured data from web pages, and web scraping has numerous applications.
What is crawling in machine learning
A Web crawler is an Internet bot that systematically browses the World Wide Web using the Internet Protocol Suite. Web Crawlers are useful in Machine Learning for collecting data that can be used for Modeling Processes such as training and prediction processing.
Is crawling a website illegal
Web scraping is completely legal if you scrape data publicly available on the internet. But some kinds of data are protected by international regulations, so be careful scraping personal data, intellectual property, or confidential data.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
How does web crawling work
Web crawlers systematically browse webpages to learn what each page on the website is about, so this information can be indexed, updated and retrieved when a user makes a search query. Other websites use web crawling bots while updating their own web content.
Is it legal to use crawler
If you're doing web crawling for your own purposes, then it is legal as it falls under fair use doctrine. The complications start if you want to use scraped data for others, especially commercial purposes.
What is the difference between crawler and robot
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
What is the purpose of a crawler
A web crawler, or spider, is a type of bot that is typically operated by search engines like Google and Bing. Their purpose is to index the content of websites all across the Internet so that those websites can appear in search engine results.
What is the advantage of crawler
The main advantage of a crawler is that they can move on site and perform lifts with very little set-up, as the crane is stable on its tracks with no outriggers. In addition, a crawler crane is capable of traveling with a load.
Why is crawling longer better
Crawling Improves Their Physical Capabilities
This help to improve their: Gross motor skills (the larger movements they make) Fine motor skills. Coordination.
What is meant by crawling process
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
What is crawling technology
Web crawlers systematically browse webpages to learn what each page on the website is about, so this information can be indexed, updated and retrieved when a user makes a search query. Other websites use web crawling bots while updating their own web content.
Is it legal to crawl YouTube
Most data on YouTube is publicly accessible. Scraping public data from YouTube is legal as long as your scraping activities do not harm the scraped website's operations. It is important not to collect personally identifiable information (PII), and make sure that collected data is stored securely.
Is scraping TikTok legal
Scraping publicly available data on the web, including TikTok, is legal as long as it complies with applicable laws and regulations, such as data protection and privacy laws.
Is data crawling ethical
Crawlers are involved in illegal activities as they make copies of copyrighted material without the owner's permission. Copyright infringement is one of the most important legal issues for search engines that need to be addressed upon.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
What is an example of web crawling
All search engines need to have crawlers, some examples are: Amazonbot is an Amazon web crawler for web content identification and backlink discovery. Baiduspider for Baidu. Bingbot for Bing search engine by Microsoft.
Is web scraping YouTube legal
Most data on YouTube is publicly accessible. Scraping public data from YouTube is legal as long as your scraping activities do not harm the scraped website's operations. It is important not to collect personally identifiable information (PII), and make sure that collected data is stored securely.
What is crawling explained
Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.

