
What is the difference between BeautifulSoup and Scrapy
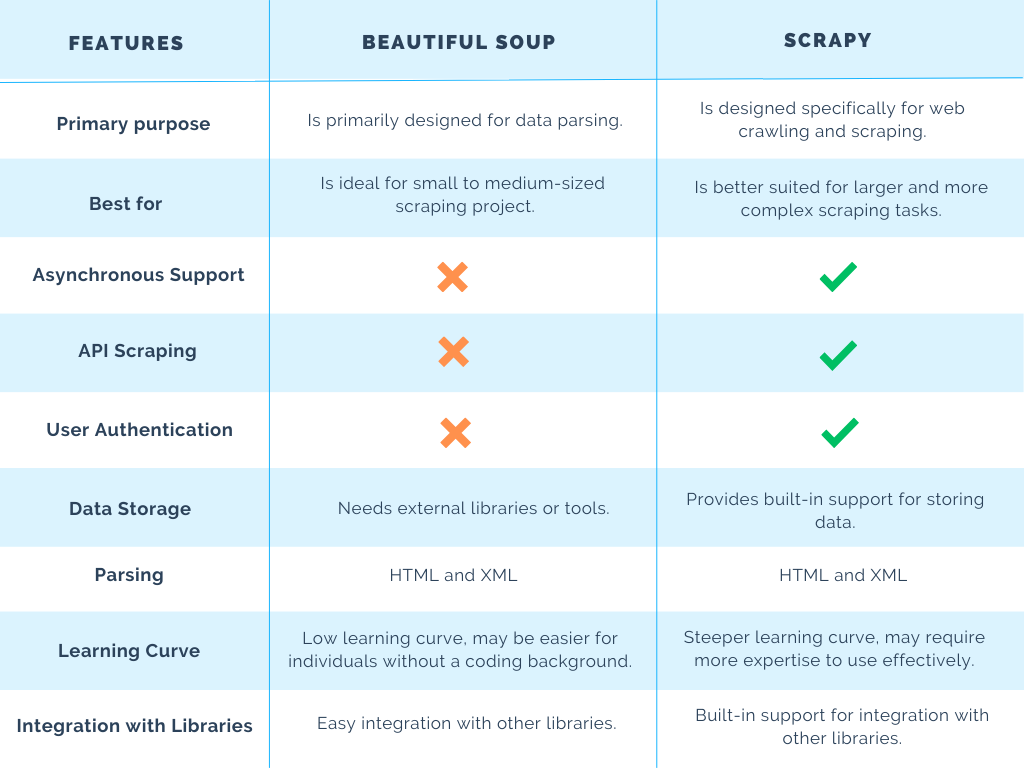
In short, the difference between Scrapy and BeautifulSoup is quite significant. Scrapy is a framework created for downloading, editing, and saving data from the web, while BeautifulSoup is a library that helps you pull data from web pages.
What is the difference between BeautifulSoup and selenium
Selenium is a web browser automation tool that can interact with web pages like a human user, whereas BeautifulSoup is a library for parsing HTML and XML documents. This means Selenium has more functionality since it can automate browser actions such as clicking buttons, filling out forms and navigating between pages.
What is the difference between Scrapy and crawler
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
Is Scrapy faster than BeautifulSoup
Performance. Scrapy is the one with the best speed since it's asynchronous, built especially for web scraping, and written in Python. However, Beautiful soup and Selenium are inefficient when scraping large amounts of data.
Which is better BeautifulSoup Selenium or Scrapy
Scrapy is the one with the best speed since it's asynchronous, built especially for web scraping, and written in Python. However, Beautiful soup and Selenium are inefficient when scraping large amounts of data.
Is Scrappy better than Selenium
The nature of work for which they're originally developed is different from one another. Selenium is an excellent automation tool and Scrapy is by far the most robust web scraping framework. When we consider web scraping, in terms of speed and efficiency Scrapy is a better choice.
What is the difference between Selenium and BeautifulSoup and Scrapy
Scrapy is the one with the best speed since it's asynchronous, built especially for web scraping, and written in Python. However, Beautiful soup and Selenium are inefficient when scraping large amounts of data.
What is a crawler in Scrapy
Scrapy uses spiders , which are self-contained crawlers that are given a set of instructions [1]. In Scrapy it is easier to build and scale large crawling projects by allowing developers to reuse their code.
What is the difference between Scrapy and BS
Scrapy is incredibly fast. Its ability to send asynchronous requests makes it hands-down faster than BeautifulSoup. This means that you'll be able to scrape and extract data from many pages at once. BeautifulSoup doesn't have the means to crawl and scrape pages by itself.
What is the best web scraping tool for Python
Top 7 Python Web Scraping Libraries & Tools in 2023Beautiful Soup.Requests.Scrapy.Selenium.Playwright.Lxml.Urllib3.MechanicalSoup.
Which framework is best for web scraping
Scrapy is the most efficient web scraping framework on this list, in terms of speed, efficiency, and features. It comes with selectors that let you select data from an HTML document using XPath or CSS elements. An added advantage is the speed at which Scrapy sends requests and extracts the data.
Which is better beautiful soup Selenium or Scrapy
Scrapy is the one with the best speed since it's asynchronous, built especially for web scraping, and written in Python. However, Beautiful soup and Selenium are inefficient when scraping large amounts of data.
What are the disadvantages of Scrapy
The first disadvantage is its complexity. Scrapy is known for its steep learning curve. If you're new to web scraping, you'd probably want to go for a beginner-friendly alternative, such as Beautiful Soup. The other disadvantage is that Scrapy cannot scrape dynamically loaded content on its own.
What is the difference between crawler and scraper in Python
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
What is the difference between web crawler and web scraper
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
What is the difference between crawler and scraping
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
Is Scrapy good for web scraping
Scrapy is a wonderful open source Python web scraping framework. It handles the most common use cases when doing web scraping at scale: Multithreading. Crawling (going from link to link)
What is the easiest web scraping library for Python
BeautifulSoup is probably the go-to library for python web scraping tools because it is easier to use for both beginners and experts. The main benefit of using BeautifulSoup is that you don't have to worry about bad HTML. BeautifulSoup and request are frequently combined in web scraping tools.
What is the fastest web scraping library for Python
Scrapy is the most efficient web scraping framework on this list, in terms of speed, efficiency, and features. It comes with selectors that let you select data from an HTML document using XPath or CSS elements. An added advantage is the speed at which Scrapy sends requests and extracts the data.
Is Scrapy enough for web scraping
Scrapy is the one with the best speed since it's asynchronous, built especially for web scraping, and written in Python. However, Beautiful soup and Selenium are inefficient when scraping large amounts of data.
What is the best web scraping tool in Python
Top 7 Python Web Scraping Libraries & Tools in 2023Beautiful Soup.Requests.Scrapy.Selenium.Playwright.Lxml.Urllib3.MechanicalSoup.
Which is better Selenium or Scrapy
The nature of work for which they're originally developed is different from one another. Selenium is an excellent automation tool and Scrapy is by far the most robust web scraping framework. When we consider web scraping, in terms of speed and efficiency Scrapy is a better choice.
What is the difference between scrapy and crawler
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
What is difference between data scraping and web scraping
Web scraping is when you take any publicly available online data and import the found information into any local file on your computer. The main difference here to data scraping is that web scraping definition requires the internet to be conducted.
What does scrapy crawl do
Scrapy provides Item pipelines that allow you to write functions in your spider that can process your data such as validating data, removing data and saving data to a database. It provides spider Contracts to test your spiders and allows you to create generic and deep crawlers as well.

