
What is the difference between data pipeline and ETL process
But what's the difference Both data pipelines and ETL are responsible for transferring data between sources and storage solutions, but they do so in different ways. Data pipelines work with ongoing data streams in real time, while ETL focuses more on individual “batches” of data for more specific purposes.
What is the difference between ETL and ETL pipeline
An ETL pipeline is a set of processes to extract data from one system, transform it, and load it into a target repository. ETL is an acronym for “Extract, Transform, and Load” and describes the three stages of the process.
What is the main difference between the ELT and ETL process
Key Difference between ETL and ELT
ETL stands for Extract, Transform and Load, while ELT stands for Extract, Load, Transform. ETL loads data first into the staging server and then into the target system, whereas ELT loads data directly into the target system.
What is the ETL pipeline process
An ETL pipeline is the set of processes used to move data from a source or multiple sources into a database such as a data warehouse. ETL stands for “extract, transform, load,” the three interdependent processes of data integration used to pull data from one database and move it to another.
What is the difference between pipelining and processing
The term “pipeline” indicates that the flow of information takes place in parallel. Pipelining defines the temporal overlapping of processing. The overlapping of processing is done by relating a register with every segment in the pipeline.
What are the different ETL processes
What is the ETL Process The 5 steps of the ETL process are: extract, clean, transform, load, and analyze. Of the 5, extract, transform, and load are the most important process steps. Clean: Cleans data extracted from an unstructured data pool, ensuring the quality of the data prior to transformation.
Can ETL process also use the pipelining concept
ETL process can also use the pipelining concept i.e. as soon as some data is extracted, it can transformed and during that period some new data can be extracted. And while the transformed data is being loaded into the data warehouse, the already extracted data can be transformed.
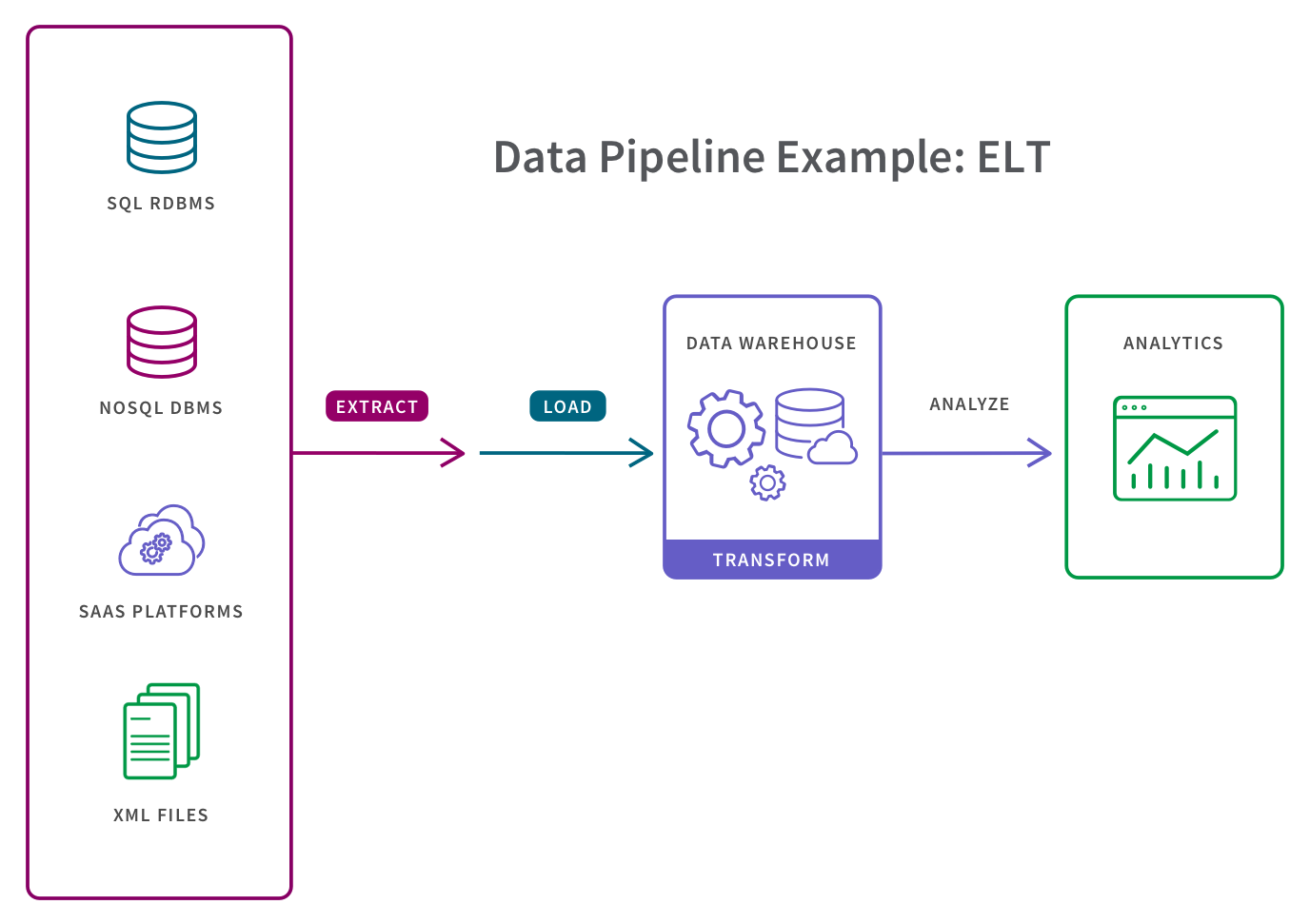
What is ETL and ELT data pipelines
ETL and ELT are data integration pipelines that transfer data from multiple sources to a single centralized source and perform some transformation and processing steps to it. The difference between these two is ETL transforms the data before loading, and ELT transforms the data after loading.
What is the difference between parallel processing and pipeline processing
In pipelining independent computations are executed in an interleaved manner, while parallel processing achieves the same using duplicate hardware. Parallel processing systems are also referred to as block processing systems. The block size indicates the number of inputs processed simultaneously.
What is the difference between pipeline and vector processing
o Pipeline processing ▪ Is an implementation technique where arithmetic sub operations or the phases of a computer instruction cycle overlap in execution. o Vector processing ▪ Deals with computations involving large vectors and matrices. o Array processing ▪ Perform computations on large arrays of data.
What is the 5 step ETL process
What is the ETL Process The 5 steps of the ETL process are: extract, clean, transform, load, and analyze. Of the 5, extract, transform, and load are the most important process steps. Clean: Cleans data extracted from an unstructured data pool, ensuring the quality of the data prior to transformation.
What are the 2 extraction types in ETL
Data extraction is divided into two categories: logical and physical. Logical extraction maintains the relationships and integrity of the data while extracting it from the source. Physical extraction, on the other hand, extracts the raw data as is from the source without considering the relationships.
What is the difference between pipelining and parallel processing
Pipelining results in faster processing because the CPU does not have to wait for one instruction to complete the machine cycle. While Parallel processing is a method in computing of running two or more processors (CPUs) to handle separate parts of an overall task.
What are the ETL process concepts
Extract, transform, and load (ETL) is the process of combining data from multiple sources into a large, central repository called a data warehouse. ETL uses a set of business rules to clean and organize raw data and prepare it for storage, data analytics, and machine learning (ML).
Is ETL part of data pipeline
An ETL pipeline is simply a data pipeline that uses an ETL strategy to extract, transform, and load data. Here data is typically ingested from various data sources such as a SQL or NoSQL database, a CRM or CSV file, etc.
Does ETL have the same process like ELT
ELT is a variation of the Extract, Transform, Load (ETL), a data integration process in which transformation takes place on an intermediate server before it is loaded into the target. In contrast, ELT allows raw data to be loaded directly into the target and transformed there.
What is the difference between pipelining and sequential processing
The data logger has two processing modes: sequential mode and pipeline mode. In sequential mode, data logger tasks run more or less in sequence. In pipeline mode, data logger tasks run more or less in parallel.
What are the 4 steps of ETL process
the ETL process: extract, transform and load. Then analyze. Extract from the sources that run your business. Data is extracted from online transaction processing (OLTP) databases, today more commonly known just as 'transactional databases', and other data sources.
What is an example of an ETL process
ETL Process Example: Extracting, Transforming, and Loading Data from a Retail Database to a Data Warehouse. A use case example of an ETL process would be a retail company that is looking to improve data management and analyse sales data from various store locations.
What are the 3 methods of extraction
Extraction is the first step to separate the desired natural products from the raw materials. Extraction methods include solvent extraction, distillation method, pressing and sublimation according to the extraction principle. Solvent extraction is the most widely used method.
What is part of ETL process
ETL is an integration process used in data warehousing, that refers to three steps (extract, transform, and load). This helps provide a single source of truth for businesses by combining data from different sources.
What are the different types of ETL process
What is the ETL Process The 5 steps of the ETL process are: extract, clean, transform, load, and analyze. Of the 5, extract, transform, and load are the most important process steps. Clean: Cleans data extracted from an unstructured data pool, ensuring the quality of the data prior to transformation.
What is the difference between pipeline and non pipeline
In pipelining system, multiple instructions are overlapped during execution. In a Non-Pipelining system, processes like decoding, fetching, execution and writing memory are merged into a single unit or a single step. The efficiency of the pipelining system depends upon the effectiveness of CPU scheduler.
What are the 4 techniques on the extraction process
Extraction methods include solvent extraction, distillation method, pressing and sublimation according to the extraction principle. Solvent extraction is the most widely used method.
What are the two types of extraction processes
There are two types of extraction, liquid-liquid extraction also known as solvent extraction as well as solid-liquid extraction. Both extraction types are based on the same principle, the separation of compounds, based on their relative solubilities in two different immiscible liquids or solid matter compound.

