
What is the difference between crawling and indexing in Google
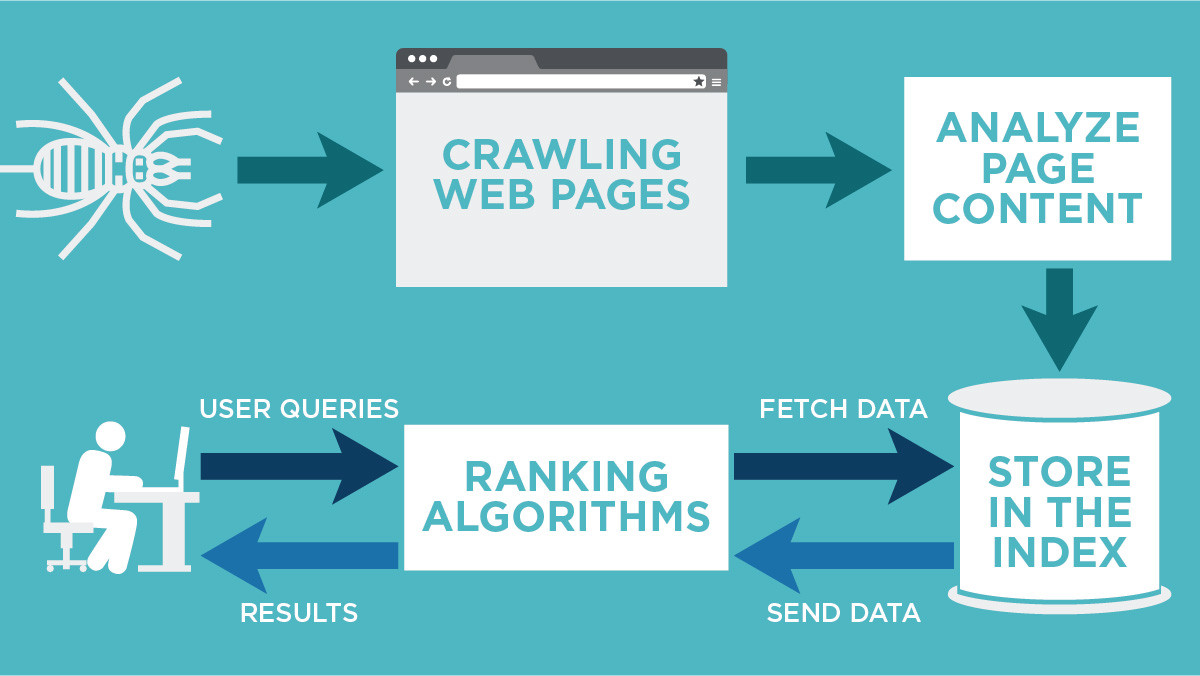
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages.
What’s the difference between crawling and indexing
Crawling: Scour the Internet for content, looking over the code/content for each URL they find. Indexing: Store and organize the content found during the crawling process. Once a page is in the index, it's in the running to be displayed as a result to relevant queries.
What is the relationship between crawlers and SEO
The Importance of a Crawler
Remember your goal as an SEO is to have your web pages rank on a search engine's results page. To be on the results page — in any rank position — a crawler needs to visit your site. A crawler's ability to access your site reveals if there are any search engine indexing issues present.
What does it mean when Google crawls
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
Why does Google crawl but not index
This product listing page was flagged as “Crawled — Currently Not Indexed”. This may be due to very thin content on the page. This page is likely either too thin for Google to think it's useful or there is so little content that Google considers it to be a duplicate of another page.
What is crawling vs indexing vs ranking
Indexing – Once a page is crawled, search engines add it to their database. For Google, crawled pages are added to the Google Index. Ranking- After indexing, search engines rank pages based on various factors. In fact, Google weighs pages against its 200+ ranking factors before ranking them.
What happens first crawling or indexing
Crawling is the very first step in the process. It is followed by indexing, ranking (pages going through various ranking algorithms) and finally, serving the search results.
How does Google crawler work in SEO
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
What does index mean in SEO
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine's index, users will not be able to find it.
What are the 3 types of search engines
There are three main types of search engines, web crawlers, directories, and sponsored links. Search engines typically use a number of methods to collect and retrieve their results. These include: Crawler databases.
How do you solve crawled but not indexed
How to fix “Crawled ‐ currently not indexed”Provide high-quality content.Monitor your index coverage.Design a sound website structure.Limit your duplicate content.
Why Google is not indexing pages
Did you recently create the page or request indexing It can take time for Google to index your page; allow at least a week after submitting a sitemap or a submit to index request before assuming a problem. If your page or site change is recent, check back in a week to see if it is still missing.
Does indexing improve performance
A properly created database index can improve query performance by 99% or more. This article covered the main considerations for creating a database index that improves performance instead of slowing it down: Index type. Selecting the correct column.
Why is indexing faster
What is Indexing Indexing makes columns faster to query by creating pointers to where data is stored within a database. Imagine you want to find a piece of information that is within a large database. To get this information out of the database the computer will look through every row until it finds it.
What is an index in SEO
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine's index, users will not be able to find it.
What is crawling and indexing the web
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
What does Google index means
The Google index is similar to an index in a library, which lists information about all the books the library has available. However, instead of books, the Google index lists all of the webpages that Google knows about. When Google visits your site, it detects new and updated pages and updates the Google index.
What is Google indexing
Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database. Serving search results: When a user searches on Google, Google returns information that's relevant to the user's query.
What are the 5 top search engines
Top Search EnginesGoogle.Bing.Yahoo!Yandex.DuckDuckGo.Baidu.Ask.com.Naver.
What are the 4 parts of search engine
A search engine normally consists of four components, as follows: a search interface, a crawler (also known as a spider or bot), an indexer, and a database.
Why is crawled but not indexed
If you've submitted a URL to Google Search Console and got the message Crawled – Currently Not Indexed, it means Google has crawled the page but chose to not index it. As a result, the URL won't appear in search results for the time being.
Why is my URL being crawled but not indexed
The 'crawled – currently not indexed' status within your page indexing report in Google Search Console means that Google has actively crawled the page on your website, but chosen not to include it in its index. This means that this page will not be showing up within Google's search engine results pages, for any query.
How do I fix crawled but not indexed
Solution: Create a temporary sitemap. xml.Export all of the URLs from the “Crawled — currently not indexed” report.Match them up in Excel with redirects that have been previously set up.Find all of the redirects that have a destination URL in the “Crawled — currently not indexed” bucket.Create a static sitemap.
Does Google index all websites
Indexing isn't guaranteed; not every page that Google processes will be indexed. Indexing also depends on the content of the page and its metadata. Some common indexing issues can include: The quality of the content on page is low.
What are the disadvantages of indexing
Disadvantages of defining an indexIndexes take up disk space. (See the Calculate index size)Indexes can slow down other processes. When the user updates an indexed column, OpenEdge updates all related indexes as well, and when the user creates or deletes a row, OpenEdge changes all the indexes for that table.

