
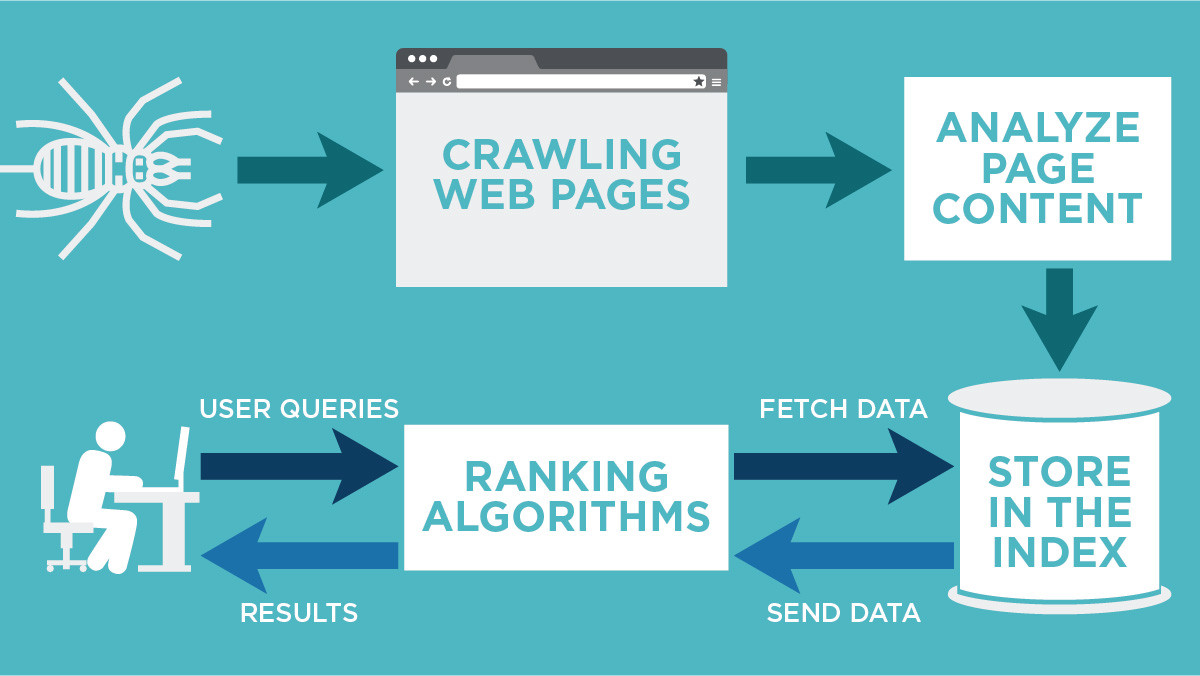
What is the purpose of a crawler marketing
A web crawler is a tool that collects content online to build a database for additional analysis. They analyze hashtags and keywords, index the URLs and the content, check if links are updated, rank pages, and more.
What are advantages of crawlers
Keeping Tabs on Competitors
Their pricing, marketing strategies, and all. With Web Crawlers, you can extract data automatically from various competitors' websites without any hassle. This provides you and your employees the opportunity to save time for other productive tasks.
What does Googlebot crawl
Googlebot is the web crawler used by Google to gather the information needed and build a searchable index of the web. Googlebot has mobile and desktop crawlers, as well as specialized crawlers for news, images, and videos.
Bản lưu
Why is crawling important in SEO
Crawling is crucial for SEO because it allows search engines to understand the content on your website and rank it based on relevance and quality. If your website is not crawled, it will not appear in search engine results pages (SERPs), which means you'll miss out on valuable organic traffic.
What is the importance of crawling in SEO
Importance of crawling and indexing for your website
If Google can't crawl your website, you won't be included in any search results. Make sure to check robots. txt. A technical SEO review of your website should reveal any other issues with search engine web crawler accessibility.
What are the applications of web crawler
What are web crawling applications Web crawling is commonly used to index pages for search engines. This enables search engines to provide relevant results for queries. Web crawling is also used to describe web scraping, pulling structured data from web pages, and web scraping has numerous applications.
What does Google Crawl let you monitor
The Crawl Stats report shows you statistics about Google's crawling history on your website. For instance, how many requests were made and when, what your server response was, and any availability issues encountered. You can use this report to detect whether Google encounters serving problems when crawling your site.
How does Google crawler work in SEO
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
Why is crawling and indexing important
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
Why is crawling longer better
Crawling Improves Their Physical Capabilities
This help to improve their: Gross motor skills (the larger movements they make) Fine motor skills. Coordination.
What is the feature of web crawler
Web crawlers copy pages for processing by a search engine, which indexes the downloaded pages so that users can search more efficiently. Crawlers consume resources on visited systems and often visit sites unprompted. Issues of schedule, load, and "politeness" come into play when large collections of pages are accessed.
Is web crawler used for data mining
Another use of Web crawlers is in Web archiving, which involves large sets of webpages to be periodically collected and archived. Web crawlers are also used in data mining, wherein pages are analyzed for different properties like statistics, and data analytics are then performed on them.
Does Google crawl hidden content
Well in general Google will only 'read' visible text. It will ignore hidden text, on the basis users dont see it either. So depending on how you implement the loading, if the text is still invisible when Googel 'renders' the page, Google will ignore the text.
Does Google crawl background images
That is correct – Google does not index background images because background images are added to the CSS, and alt-text is an attribute added to the image tag (HTML) that search engines can crawl.
Why is crawling important in research
Research has shown that baby crawling increases hand-eye coordination, gross and fine motor skills (large and refined movements), balance, and overall strength.
Is crawling the same as indexing
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.
How effective is crawling
Fundamental movements, like crawling, are necessities for moving around in your everyday life. Crawling can help you tone your body and increase your strength. And the best part is—it's easy to incorporate into your life. You don't need to go to the gym or even designate a time to work out.
What is the impact of crawling
Crawling helps babies to develop gross motor skills in several ways, especially when it is a proper crawl- the typical hands and knees/quadruped crawl often associated with babies. One way it helps is by strengthening the baby's muscles.
How does a crawler work in SEO
A crawler is a program used by search engines to collect data from the internet. When a crawler visits a website, it picks over the entire website's content (i.e. the text) and stores it in a databank. It also stores all the external and internal links to the website.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Where does web crawler store data
Web crawlers, while they're on the page, gather information about the page like the copy and meta tags. Then, the crawlers store the pages in the index, so Google's algorithm can sort them for their contained words to later fetch and rank for users.
How do web crawlers contribute to spam
These spam bots crawl your pages, ignoring rules like those found in robots. txt, otherwise known as the Robot Exclusion Standard or Robot Exclusion Protocol. This standard is used by websites to tell web crawlers and other web robots what parts of the website not to process or scan.
Does Google crawl all websites
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
Does Google crawl hidden pages
Well in general Google will only 'read' visible text. It will ignore hidden text, on the basis users dont see it either. So depending on how you implement the loading, if the text is still invisible when Googel 'renders' the page, Google will ignore the text.
What is crawling vs indexing in SEO
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.

