
What is web data crawling
What is crawling Web crawling (or data crawling) is used for data extraction and refers to collecting data from either the world wide web or, in data crawling cases – any document, file, etc. Traditionally, it is done in large quantities.
What is web scraping and web crawling in Python
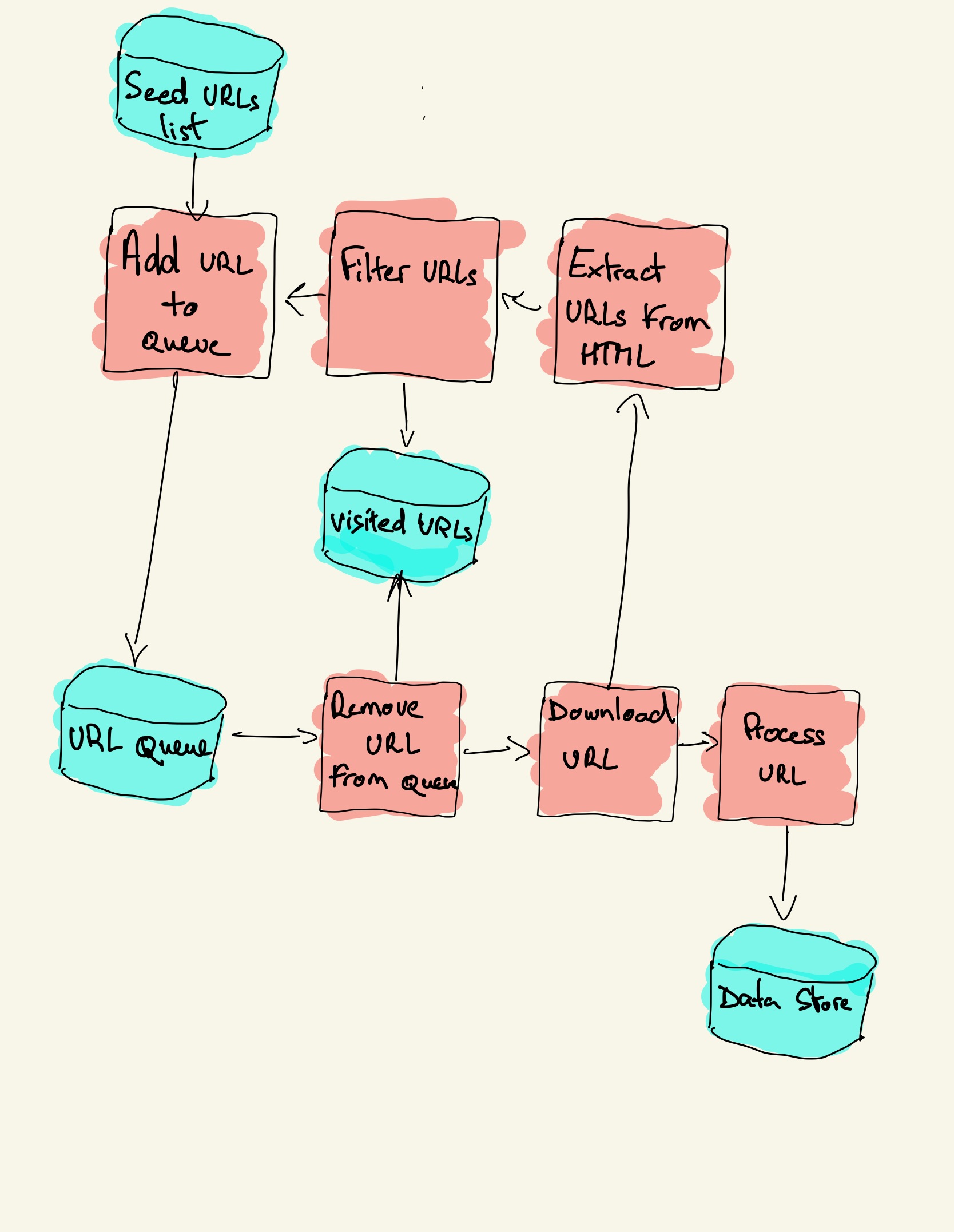
Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code. A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue.
What is the difference between web crawler and bot
Crawler- A program that automatically follows all of the links on each web page. Robots- An automated computer program that visits websites and perform predefined tesk. They are guided by search engine algorithms and are able to perform different tasks instead of just one crawling task.
How is web crawling done
A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
How to do web crawling using Python
Make a web crawler using Python ScrapySetting up Scrapy. Open your cmd prompt. Run the command:Fetching the website. Use the fetch command to get the target webpage as a response object.Extracting Data from the website. Right-click the first product title on the page and select inspect element.
Is web scraping same as web crawling
Web scraping aims to extract the data on web pages, and web crawling purposes to index and find web pages. Web crawling involves following links permanently based on hyperlinks. In comparison, web scraping implies writing a program computing that can stealthily collect data from several websites.
Is web scraping same as crawling
The short answer. The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
Why is web crawling used
Web crawlers systematically browse webpages to learn what each page on the website is about, so this information can be indexed, updated and retrieved when a user makes a search query. Other websites use web crawling bots while updating their own web content.
Is Google a web crawler
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.
Which algorithm is used for web crawling
The first three algorithms given are some of the most commonly used algorithms for web crawlers. A* and Adaptive A* Search are the two new algorithms which have been designed to handle this traversal. Breadth First Search is the simplest form of crawling algorithm.
Is it easy to learn web crawling
Web crawling/scrapping is a very fancy term talked and heard now days, but very less people are aware, performing web crawling is very easy and any one can do with basic linux or any os skills without any programming knowledge.
Is web crawling machine learning
A Web crawler is an Internet bot that systematically browses the World Wide Web using the Internet Protocol Suite. Web Crawlers are useful in Machine Learning for collecting data that can be used for Modeling Processes such as training and prediction processing.
What is spider vs crawler vs scraper
A crawler(or spider) will follow each link in the page it crawls from the starter page. This is why it is also referred to as a spider bot since it will create a kind of a spider web of pages. A scraper will extract the data from a page, usually from the pages downloaded with the crawler.
Which language is best for web crawling
Top 5 programming languages for web scrapingPython. Python web scraping is the go-to choice for many programmers building a web scraping tool.Ruby. Another easy-to-follow programming language with a simple-to-understand syntax is Ruby.C++JavaScript.Java.
Is it illegal to web crawler
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
Is Yahoo a web crawler
Search engines like Google, Bing, and Yahoo use crawlers to properly index downloaded pages so that users can find them faster and more efficiently when searching. Without web crawlers, there would be nothing to tell them that your website has new and fresh content.
Is web scraping the same as web crawling
The short answer is that web scraping is about extracting data from one or more websites. While crawling is about finding or discovering URLs or links on the web. Usually, in web data extraction projects, you need to combine crawling and scraping.
Are web crawlers and spiders the same
A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web and that is typically operated by search engines for the purpose of Web indexing (web spidering).
Can you get IP banned for web scraping
Having your IP address(es) banned as a web scraper is a pain. Websites blocking your IPs means you won't be able to collect data from them, and so it's important to any one who wants to collect web data at any kind of scale that you understand how to bypass IP Bans.
Are web crawlers harmful
Crawlers have a wide variety of uses on the internet. They automatically search through documents online. Website operators are mainly familiar with web crawlers from search engines such as Google or Bing; however, crawlers can also be used for malicious purposes and do harm to companies.
Is web scraping better than API
With web scraping, you have more control over how much data you want to collect and how often you want to scrape for new information. This allows for greater flexibility compared to using APIs which may offer more limited options in terms of data collection and frequency.
Are web crawlers illegal
United States: There are no federal laws against web scraping in the United States as long as the scraped data is publicly available and the scraping activity does not harm the website being scraped.
Are web crawlers bad
Bad bots. While most web crawlers are benign, some can be used for malicious purposes. These malicious web crawlers, or "bots," can be used to steal information, launch attacks, and commit fraud. It has also been increasingly found that these bots ignore robots.
Do I need VPN for web scraping
Most web scrapers need proxies to scrape without being blocked. However, proxies can be expensive and out of reach for many small web scrapers. One alternative to proxies is to use personal VPN services as proxy clients.
Do hackers use web scraping
A scraping bot can gather user data from social media sites. Then, by scraping sites that contain addresses and other personal information and correlating the results, a hacker could engage in identity crimes like submitting fraudulent credit card applications.

