
Which classifier is best for large dataset
2.3 Stochastic Gradient Descent
Definition: Stochastic gradient descent is a simple and very efficient approach to fit linear models. It is particularly useful when the number of samples is very large. It supports different loss functions and penalties for classification.
Which algorithm is best for large data
Quicksort is probably more effective for datasets that fit in memory. For larger data sets it proves to be inefficient so algorithms like merge sort are preferred in that case. Quick Sort is an in-place sort (i.e. it doesn't require any extra storage) so it is appropriate to use it for arrays.
Which classifier is best in deep learning
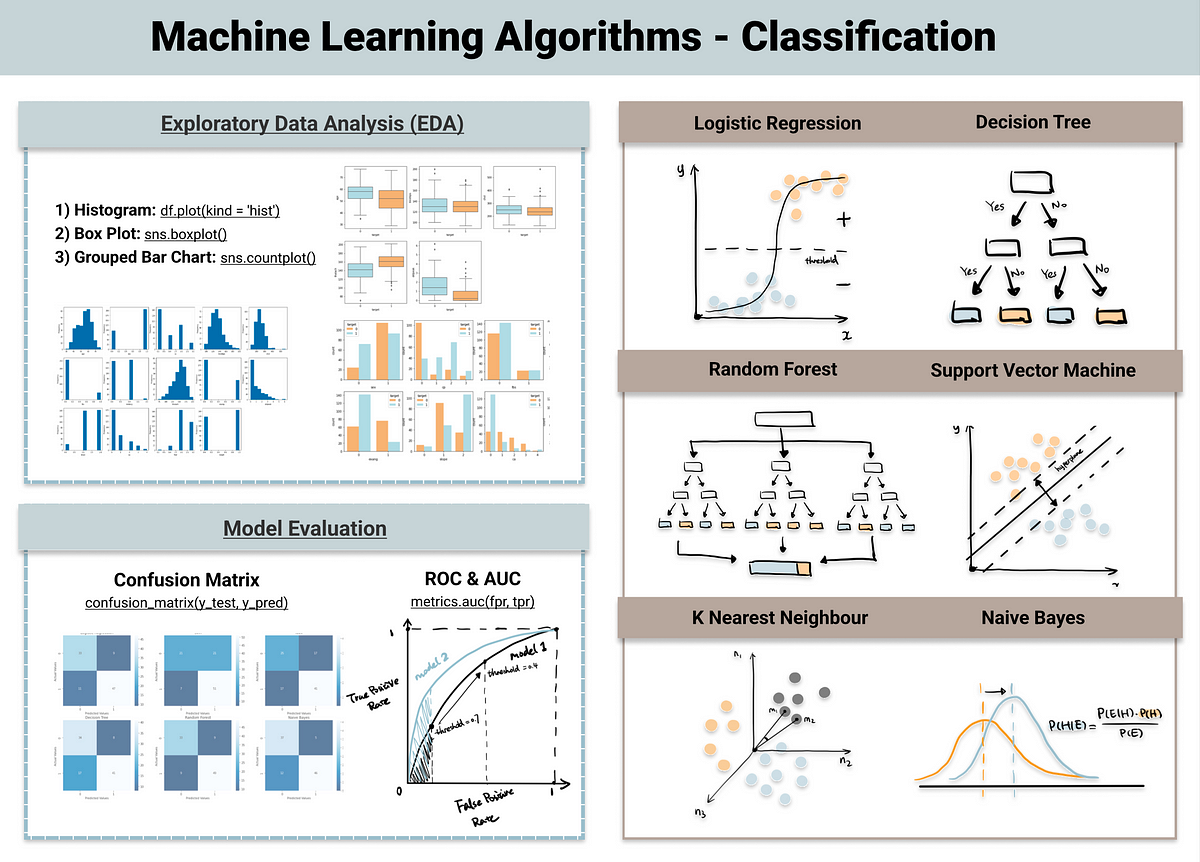
Our chosen ML algorithms for classification are:Logistic Regression.Naive Bayes.K-Nearest Neighbors.Decision Tree.Support Vector Machines.
Which is the best classifier algorithm
Top 5 Classification Algorithms in Machine LearningLogistic Regression.Naive Bayes.K-Nearest Neighbors.Decision Tree.Support Vector Machines.
Is K-Means good for large datasets
While K-Means allows for clustering of data, and is scalable, it isn't capable of handling large datasets by itself. K-Means can be used based on MapReduce to manage and manipulate large datasets.
Is Naive Bayes good for large datasets
Large and sparse datasets with a lot of missing values are common in the big data era. Naive Bayes is a good classification algorithm for such datasets, as its time and space complexity scales well with the size of non-missing values.
Which sorting algorithm is best for large dataset and why
Quick sort is the better suited for large data sets. [8]It is the fastest and efficient algorithm for large sets of data. But it is inefficient if the elements in the list are already sorted which results in the worst case time complexity of O(n2).
Which sort is fastest for large data
Quicksort is the fastest known comparison-based sorting algorithm when applied to large, unordered, sequences. It also has the advantage of being an in-place (or nearly in-place) sort. Unfortunately, quicksort has some weaknesses: it's worst-case performance is O(n2) O ( n 2 ) , and it is not stable.
Which classifier is better than XGBoost
Both the algorithms perform similarly in terms of model performance but LightGBM training happens within a fraction of the time required by XGBoost. Fast training in LightGBM makes it the go-to choice for machine learning experiments.
Is Bayes optimal classifier the best
Selecting the outcome with the maximum probability is an example of a Bayes optimal classification. Any model that classifies examples using this equation is a Bayes optimal classifier and no other model can outperform this technique, on average.
Which classifier is better SVM or random forest
Model accuracy by Random Forest classifier. Model accuracy by SVM classifier. It is because in this dataset, data is sparse and easy to classify, hence SVM works faster and provides better results. However, random forest also gives good results but does not match upto SVM for this particular dataset.
Is KNN good for large datasets
The KNN algorithm does not work well with large datasets. The cost of calculating the distance between the new point and each existing point is huge, which degrades performance. Feature scaling (standardization and normalization) is required before applying the KNN algorithm to any dataset.
Is clustering good for large datasets
Traditional K-means clustering works well when applied to small datasets. Large datasets must be clustered such that every other entity or data point in the cluster is similar to any other entity in the same cluster. Clustering problems can be applied to several clustering disciplines [3].
Is Naive Bayes more accurate than KNN on large datasets
If speed is important, choose Naive Bayes over K-NN. 2. In general, Naive Bayes is highly accurate when applied to big data. Don't discount K-NN when it comes to accuracy though; as the value of k in K-NN increases, the error rate decreases until it reaches that of the ideal Bayes (for k→∞).
Which is better SVM or Naive Bayes
It has been generally observed that SVM performs better and return higher accuracy than Naïve Bayes. In this article, we will perform image classification on the fine-tuned dataset by Caltech to see whether this assumption regarding SVM and Naïve Bayes is correct.
Is merge sort good for large data
The merge sort algorithm has several advantages over other sorting algorithms: it can be implemented with a few lines of code; it performs well on large datasets; it is relatively simple to understand; and its time complexity is O(n log n) which makes it faster than insertion or bubble sorts.
Is heap sort good for large data sets
Sorting: Heap sort can efficiently sort an array of elements in ascending or descending order. It has a worst-case time complexity of O(n log n), which makes it suitable for sorting large data sets.
How do I sort large datasets
Sorting a large data set requires a large amount of storage space and temporary space. To save space, if possi- ble, we should make the dataset we want to sort smaller by dropping unnecessary variables, and using the neces- sary lengths for variables. We can also use COMPRESS option to compress the original dataset.
Is SVM better than XGBoost
Compared with the SVM model, the XGBoost model generally showed better performance for training phase, and slightly weaker but comparable performance for testing phase in terms of accuracy. However, the XGBoost model was more stable with average increase of 6.3% in RMSE, compared to 10.5% for the SVM algorithm.
Is KNN better than XGBoost
With an AUC score of 87.52 %, the final analysis showed that KNN had the highest prediction accuracy, followed by Random Forest (84.34 %) and XGBoost (78.07%). According to the AUC findings, KNN, Random Forest, and XGBoost performed consistently well in forecasting landslide susceptibility.
Which classifier is better Naive Bayes or KNN
A general difference between KNN and other models is the large real time computation needed by KNN compared to others. KNN vs naive bayes : Naive bayes is much faster than KNN due to KNN's real-time execution. Naive bayes is parametric whereas KNN is non-parametric.
Is Random Forest better than LSTM
Thus, in [12], authors have showed that the random forest technique has given better performance compared to other machine learning techniques. Similarly, in [32], authors have created a random forest classifier with LSTM to encode amino acids called as LEMP that gives better performance.
Which classifier is better random forest or XGBoost
RF is a bagging technique that trains multiple decision trees in parallel and determines the final output via a majority vote. XGBoost is a boosting technique that sequentially creates decision trees, each tree improving upon the mistakes of the previous one. The final result is a sum of outputs from all the trees.
Is SVM suitable for large datasets
Support vector machine (SVM) is a powerful technique for data classification. Despite of its good theoretic foundations and high classification accuracy, normal SVM is not suitable for classification of large data sets, because the training complexity of SVM is highly dependent on the size of data set.
Why KNN is not used for large datasets
The KNN algorithm does not work well with large datasets. The cost of calculating the distance between the new point and each existing point is huge, which degrades performance.

