
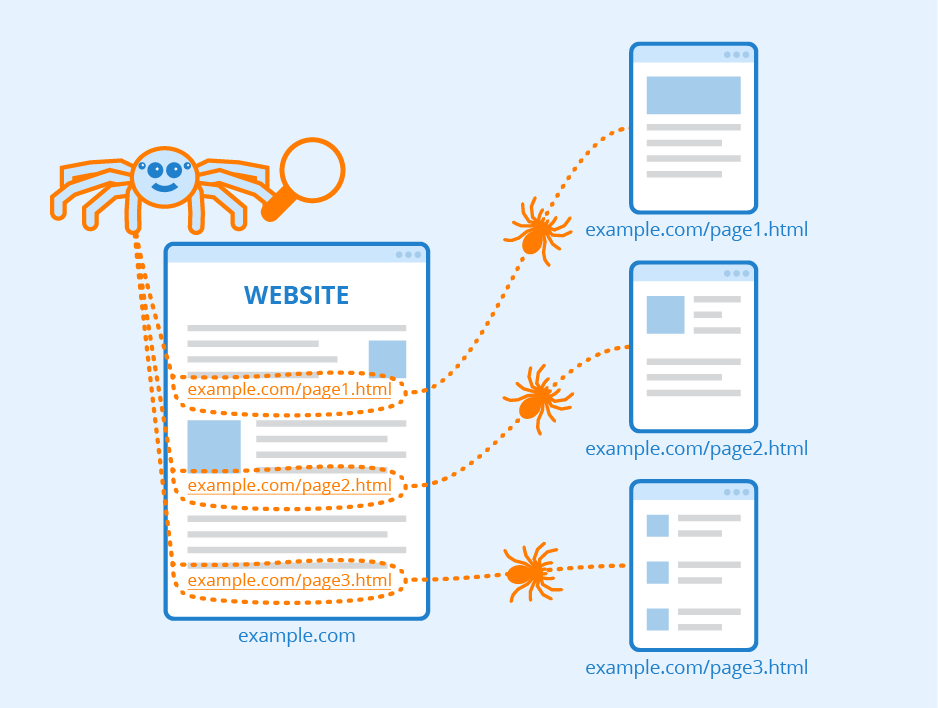
What is an example of a crawler search engine
These types of search engines use a "spider" or a "crawler" to search the Internet. The crawler digs through individual web pages, pulls out keywords and then adds the pages to the search engine's database. Google and Yahoo are examples of crawler search engines.
Is Google a search engine or a web crawler
Google Search is a fully-automated search engine that uses software known as web crawlers that explore the web regularly to find pages to add to our index.
What is crawling search
Crawling is the process of finding new or updated pages to add to Google (Google crawled my website). One of the Google crawling engines crawls (requests) the page. The terms "crawl" and "index" are often used interchangeably, although they are different (but closely related) actions.
Are web spiders and crawlers examples of search engine
A search engine spider, also known as a web crawler, is an Internet bot that crawls websites and stores information for the search engine to index.
Is Yahoo a crawler based search engine
Starting on April 7, 2003, Yahoo! Search became its own web crawler-based search engine.
Is Bing a crawler based search engine
Crawler databases.
The search engine sends out many 'crawlers' which trawl the Web randomly, following links and indexing page content as they go. Some common crawlers are the GoogleBot and MSNBot which power Google and Bing.
Why is Google a crawler based search engine
Crawler based search engines use crawling methods to gather data online. The bot combs throughout the online data gallery and looks for indexable content. Google and Yahoo are two popular crawler based search engines. The crawlers take every URL into account, list down keywords, and add them to the database.
What is a crawler in Google
"Crawler" (sometimes also called a "robot" or "spider") is a generic term for any program that is used to automatically discover and scan websites by following links from one web page to another. Google's main crawler is called Googlebot.
Is Yahoo a web crawler
Search engines like Google, Bing, and Yahoo use crawlers to properly index downloaded pages so that users can find them faster and more efficiently when searching. Without web crawlers, there would be nothing to tell them that your website has new and fresh content.
Is meta crawler a search engine
MetaCrawler is a search engine. It is a registered trademark of InfoSpace and was created by Erik Selberg. It was originally a metasearch engine, as its name suggests.
Is Yahoo a crawler search engine
Yahoo provides effective web search features to users. It uses powerful algorithm and crawlers that helps it to list the webpages related to user query and keywords.
What are the 3 types of search engine
There are three main types of search engines, web crawlers, directories, and sponsored links. Search engines typically use a number of methods to collect and retrieve their results. These include: Crawler databases.
How many types of Google crawlers are there
Google has now added new details that explain the three categories its Google crawlers fall into, they include Googlebot, special-case crawlers and user-triggered fetchers. In addition, Google now lists a JSON formatted file containing the list of IP addresses each of these different crawler types use.
Is Bing a web crawler
Bing is a search engine owned by Microsoft and Bingbot is their standard crawler that handles most of the sites' crawling on a daily basis, for both desktop and mobile web! Bing operates five main crawlers: Bingbot. The standard crawler in charge of crawling and indexing sites.
What are the 5 top search engines
Here are the top search engines in the world.The Best Search Engine in The World: Google.Search Engine #2. Bing.Search Engine #3. Baidu.Search Engine #4.Yahoo!Search Engine #5. Yandex.Search Engine #6. Ask.Search Engine #7. DuckDuckGo.Search Engine #8. Naver.
What is the 5 most commonly used search engine
Top Search EnginesGoogle.Bing.Yahoo!Yandex.DuckDuckGo.Baidu.Ask.com.Naver.
What is the name of Google crawler
Googlebot is the generic name for Google's two types of web crawlers: Googlebot Desktop: a desktop crawler that simulates a user on desktop. Googlebot Smartphone: a mobile crawler that simulates a user on a mobile device.
What is web crawler types
To make a list of web crawlers, you need to know the 3 main types of web crawlers: In-house web crawlers. Commercial web crawlers. Open-source web crawlers.
What are the 4 types of search engines
Search engines are classified into the following categories according to how it works:Crawler based search engines. Crawler-based search engines use a crawler or bot to crawl and index the new content.Human-powered directories.Hybrid search engines.Meta search engines.Specialty search engines.
What are the 3 types of search engines
There are three main types of search engines, web crawlers, directories, and sponsored links. Search engines typically use a number of methods to collect and retrieve their results. These include: Crawler databases.
What are search engines 5 examples
Search engines are listed by the statistics of Statcounter.Google.Bing.Yahoo.Baidu.DuckDuckGo.Yandex.Ask.com.Ecosia.
What is Google also called web crawler
Google is most definitely a web crawler. They operate a web crawler with the name of Googlebot which searches for new websites, crawls them, and saves them in the massive search engine database.
What is a 3 example of search engine
Popular examples of search engines are Google, Yahoo!, and MSN Search. Search engines utilize automated software applications (referred to as robots, bots, or spiders) that travel along the Web, following links from page to page, site to site.

