
What is the purpose of a classifier
What is a Classifier In data science, a classifier is a type of machine learning algorithm used to assign a class label to a data input. An example is an image recognition classifier to label an image (e.g., “car,” “truck,” or “person”).
What is the importance of classification algorithms in machine learning
The Classification algorithm is a Supervised Learning technique that is used to identify the category of new observations on the basis of training data. In Classification, a program learns from the given dataset or observations and then classifies new observation into a number of classes or groups.
What is meant by classifier in machine learning
Classifiers are algorithms in machine learning that are used to categorise data into distinct groups or classes. They are essentially mathematical models that use statistical analysis and optimisation to identify patterns in the data. These patterns help to determine the class or category that each instance belongs to.
Which classifier is best in machine learning
Naive Bayes classifier algorithm gives the best type of results as desired compared to other algorithms like classification algorithms like Logistic Regression, Tree-Based Algorithms, Support Vector Machines. Hence it is preferred in applications like spam filters and sentiment analysis that involves text.
What is the purpose of classification in data analysis
Data classification is the process of organizing data according to relevant categories for efficient usage. It helps to locate and retrieve data quickly. This process is vital when it comes to security, compliance, and risk management.
Why do we use classification in data science
Using data classification helps organizations maintain the confidentiality, ease of access and integrity of their data. For unstructured data in particular, data classification lowers the vulnerability of sensitive information.
What would be a good use of classification algorithms
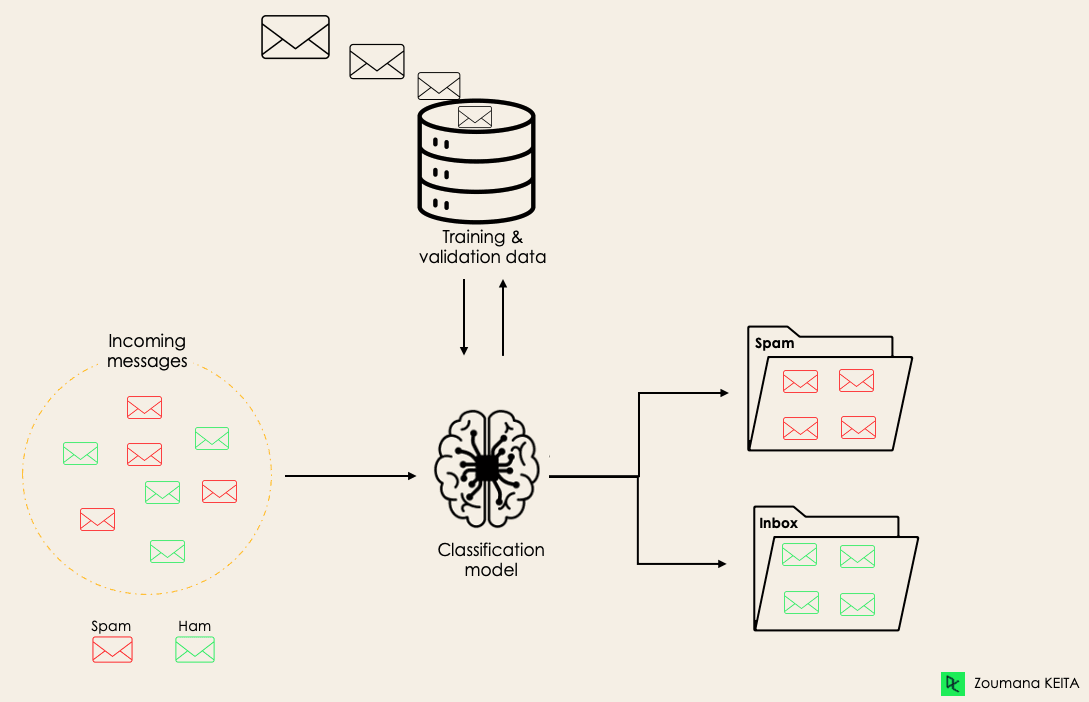
One of the most common uses of classification is filtering emails into “spam” or “non-spam.” In short, classification is a form of “pattern recognition,” with classification algorithms applied to the training data to find the same pattern (similar words or sentiments, number sequences, etc.)
What is the difference between classifier and regression
The key distinction between Classification vs Regression algorithms is Regression algorithms are used to determine continuous values such as price, income, age, etc. and Classification algorithms are used to forecast or classify the distinct values such as Real or False, Male or Female, Spam or Not Spam, etc.
What is model vs classifier in machine learning
Machine Learning FAQ
Essentially, the terms “classifier” and “model” are synonymous in certain contexts; however, sometimes people refer to “classifier” as the learning algorithm that learns the model from the training data.
Which classifier is best for large datasets
2.3 Stochastic Gradient Descent
It is particularly useful when the number of samples is very large. It supports different loss functions and penalties for classification. Advantages: Efficiency and ease of implementation. Disadvantages: Requires a number of hyper-parameters and it is sensitive to feature scaling.
What are the main benefits of data classification
By using data classification to improve how your organization is able to locate and retrieve sensitive data, your business is able to both better identify and protect data based on its risk as well as improve compliance processes.
What is benefit of data classification
Classifying data makes it possible to establish exactly what is there, where it is stored, and how valuable it is. It also helps the business to identify what can be archived or deleted, and so avoid the high protection, storage and retention costs associated with hoarding vast amounts of data.
What are advantages of classification of data
Data classification helps to protect your valuable data and improves data security. Once you identify the different types of data in your network, you can separate your sensitive data from general data. In turn, this allows you to: Prioritize your security measures.
Which method of classification is best and why
In Biology, "Taxonomical classification" is the "best method of classification". Explanation: This is because, all living organisms are needed to be classified in groups, so as to find out their similarities and their differences.
What are the applications of classification and regression algorithms
Problems like Spam Email Classification, Disease prediction like problems are solved using Classification Algorithms. Problems like House Price Prediction, Rainfall Prediction like problems are solved using regression Algorithms.
Why classification instead of regression
The most significant difference between regression vs classification is that while regression helps predict a continuous quantity, classification predicts discrete class labels. There are also some overlaps between the two types of machine learning algorithms.
Why use classification over regression
The key distinction between Classification vs Regression algorithms is Regression algorithms are used to determine continuous values such as price, income, age, etc. and Classification algorithms are used to forecast or classify the distinct values such as Real or False, Male or Female, Spam or Not Spam, etc.
Is CNN a classifier
In machine learning, a classifier assigns a class label to a data point. For example, an image classifier produces a class label (e.g, bird, plane) for what objects exist within an image. A convolutional neural network, or CNN for short, is a type of classifier, which excels at solving this problem!
What is the difference between classifier and algorithm
A classifier is the algorithm itself – the rules used by machines to classify data. A classification model, on the other hand, is the end result of your classifier's machine learning. The model is trained using the classifier, so that the model, ultimately, classifies your data.
Which classifier is better SVM or random forest
Model accuracy by Random Forest classifier. Model accuracy by SVM classifier. It is because in this dataset, data is sparse and easy to classify, hence SVM works faster and provides better results. However, random forest also gives good results but does not match upto SVM for this particular dataset.
What are three advantages of classification
It facilitates the identification of organisms. It explains how different creatures interact with one another. It aids in the comprehension of organism evolution. It helps to understand how animals, plants, and other living creatures are related and how they can benefit humans.
What is the importance of classification
It helps us understand the inter-relationship among different groups of organisms. To understand and study the features, similarities, and differences between different living organisms and how they are grouped under different categories. It helps to know the origin and evolution of organisms.
What are 3 reasons why classification is useful
It is necessary for knowing the different varieties of organisms. It helps in the correct identification of various organisms. It helps to know the origin and evolution of organisms. It helps to determine the exact position of the organism in the classification.
What is the main advantage of classification of data
Using data classification helps organizations maintain the confidentiality, ease of access and integrity of their data. For unstructured data in particular, data classification lowers the vulnerability of sensitive information.
Why should we use classification over regression
The main difference between Regression and Classification algorithms that Regression algorithms are used to predict the continuous values such as price, salary, age, etc. and Classification algorithms are used to predict/Classify the discrete values such as Male or Female, True or False, Spam or Not Spam, etc.

