
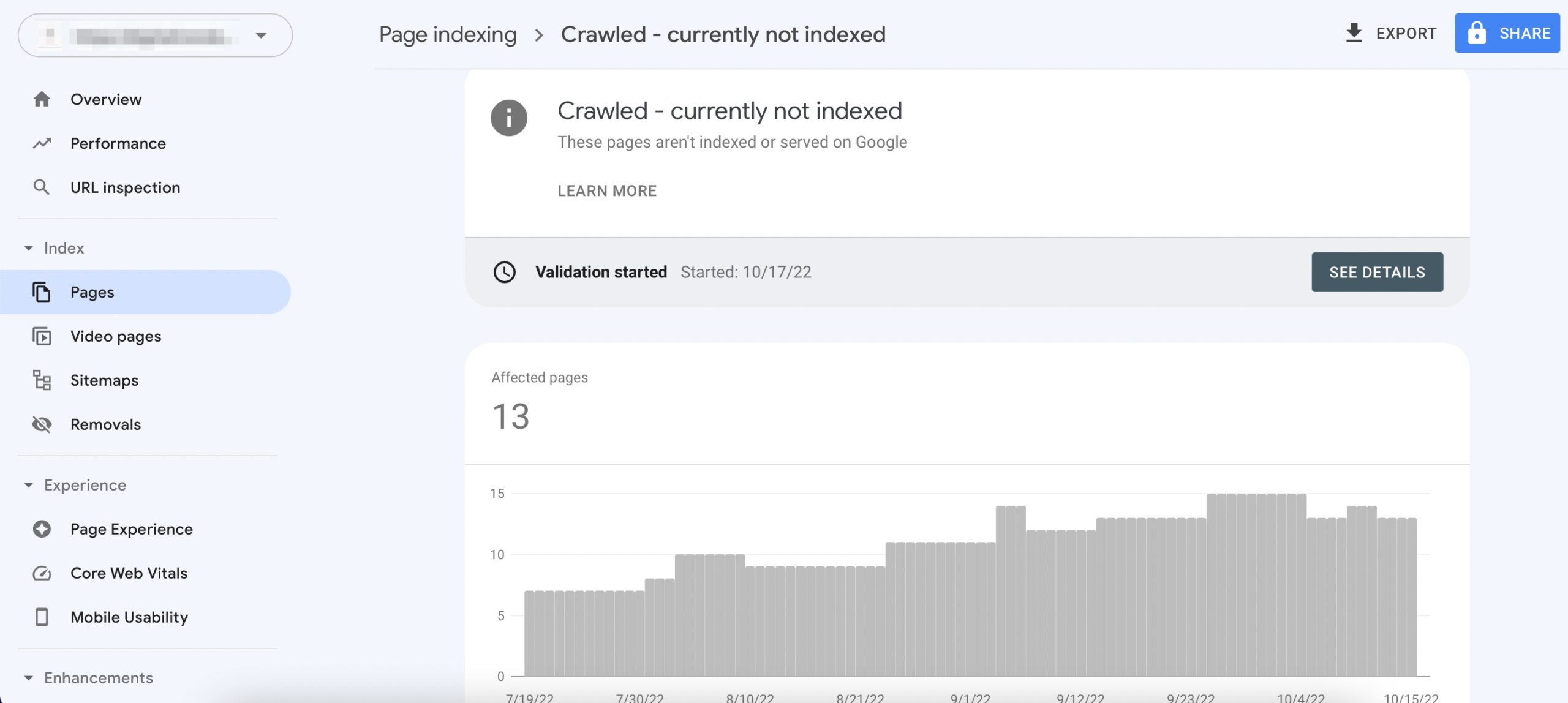
Why is crawled but not indexed
If you've submitted a URL to Google Search Console and got the message Crawled – Currently Not Indexed, it means Google has crawled the page but chose to not index it. As a result, the URL won't appear in search results for the time being.
Why would a product not be indexed
Large ecommerce websites often have products that are very similar to one another. These products may only differ by a small specification or one digit in their SKU number. In these cases of near-duplication, Google may choose to not index some of the pages.
Why would a page not be indexed
Status. A URL can have one of the following statuses: Not indexed: The URL is not indexed, either because of an indexing error, or because of a legitimate reason (for example, if the page is blocked from indexing by your robots. txt file, or is a duplicate page).
Why is Google not indexing
Google won't index your site if you're using a coding language in a complex way. It doesn't matter what the language is – it could be old or even updated, like JavaScript – as long as the settings are incorrect and cause crawling and indexing issues.
What is crawled vs indexed
Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.
What happens first crawling or indexing
Crawling is the very first step in the process. It is followed by indexing, ranking (pages going through various ranking algorithms) and finally, serving the search results.
What does it mean when it says not indexed
The Discovered – currently not indexed status means that Google knows about these URLs, but they haven't crawled (and therefore indexed) them yet. If you're running a small website (below 10.000 pages) with good quality content, this URL state is will automatically resolve after Google's crawled the URLs.
What does no indexing mean
A noindex tag informs search engines not to index a page or website, excluding it from appearing in search engine results.
How do I fix a crawled but not indexed page
How to fix Crawled – currently not indexedImprove internal linking.Thin content/ Low-quality content.Search Intent.Page with near-duplicate content.Structured data mismatch.Expired products.301 redirects.Private content.
Why did Google stop crawling my site
Did you recently create the page or request indexing It can take time for Google to index your page; allow at least a week after submitting a sitemap or a submit to index request before assuming a problem. If your page or site change is recent, check back in a week to see if it is still missing.
How do I force Google to reindex
Request indexing through Google Search ConsoleLog on to Google Search Console.Choose a property.Submit a URL from the website you want to get recrawled.Click the Request Indexing button.Regularly check the URL in the Inspection Tool.
What is crawling vs indexing vs ranking
Indexing – Once a page is crawled, search engines add it to their database. For Google, crawled pages are added to the Google Index. Ranking- After indexing, search engines rank pages based on various factors. In fact, Google weighs pages against its 200+ ranking factors before ranking them.
Is crawling and indexing the same
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages. There are parts of indexing that help inform how a search engine crawls.
What is indexing in crawling
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
Is no index bad for SEO
Making low-quality pages non-indexable is one of SEO best practices for optimizing your indexing strategy – and using the noindex meta tag is one of the most optimal ways to keep a page out of Google's index.
How do I fix no index
If you're getting the Submitted URL Marked 'noindex' error message, try these steps:Step 1 | Check the URL.Step 2 | Make sure search engines can index your page and site.Step 3 | Check if the page is password protected.Step 4 | Check if the page is a members only page.Step 5 | Use the URL Inspection Tool.
Why is 0 indexing better
As you can see, it is a lot easier to 0-based array indexing because you can calculate the nth term a lot easier without having to subtract 1 from n before multiplying the common difference. That's exactly 1 scenario where 0-based indexing might come in handy.
Why are my pages discovered but not indexed
If you see “Discovered – currently not indexed” in Google Search Console, it means Google is aware of the URL, but hasn't crawled and indexed it yet. It doesn't necessarily mean the page will never be processed. As their documentation says, they may come back to it later without any extra effort on your part.
How do I force Google to index a page
How to get indexed by GoogleGo to Google Search Console.Navigate to the URL inspection tool.Paste the URL you'd like Google to index into the search bar.Wait for Google to check the URL.Click the “Request indexing” button.
How do I force Google to crawl
Here's Google's quick two-step process:Inspect the page URL. Enter in your URL under the “URL Prefix” portion of the inspect tool.Request reindexing. After the URL has been tested for indexing errors, it gets added to Google's indexing queue.
How can I keep Google from indexing my website */
noindex is a rule set with either a <meta> tag or HTTP response header and is used to prevent indexing content by search engines that support the noindex rule, such as Google.
How long does Google take to re index
As a rule of thumb, we usually estimate: 3–4 weeks for websites with less than 500 pages. 2–3 months for websites with 500 to 25,000 pages.
How do I get Google to crawl my website again
Submit a URL from the website you want to get recrawled. Click the Request Indexing button. Regularly check the URL in the Inspection Tool. Monitor the crawling and indexing table to see when Google last recrawled your website.
What is the difference between crawl and index
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
What’s the difference between crawling and indexing
Crawling: Scour the Internet for content, looking over the code/content for each URL they find. Indexing: Store and organize the content found during the crawling process. Once a page is in the index, it's in the running to be displayed as a result to relevant queries.

