
Why clustering is better than classification
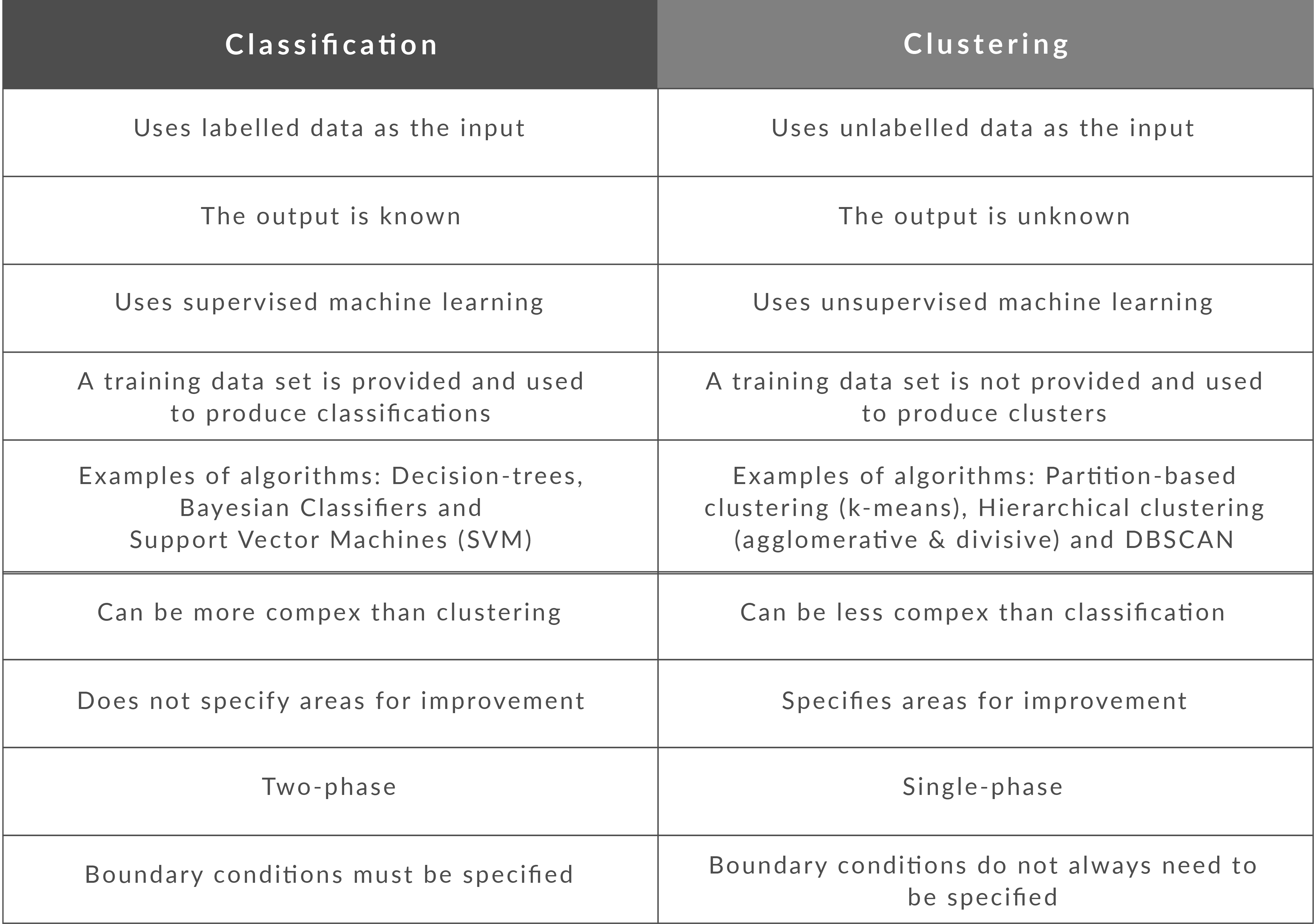
Although both techniques have certain similarities, the difference lies in the fact that classification uses predefined classes in which objects are assigned, while clustering identifies similarities between objects, which it groups according to those characteristics in common and which differentiate them from other …
When would you use clustering rather than classification
Classification is used for supervised learning in machine learning. Clustering is used for unsupervised learning in machine learning. Classification contains labels. Therefore, training and testing of the datasets is necessary in order to verify the model.
How is clustering different than classification
What Is the Basic Difference Between Classification and Clustering Classification sorts data into specific categories using a labeled dataset. Clustering is partitioning an unlabeled dataset into groups of similar objects.
Why clustering is not classification
Clustering is an example of an unsupervised learning algorithm, in contrast to regression and classification, which are both examples of supervised learning algorithms. Data may be labeled via the process of classification, while instances of similar data can be grouped together through the process of clustering.
Which is better classification or clustering
Classification is more complex as compared to clustering. Clustering is less complex as compared to the classification. Here, we utilised the labels for training data.
What is the advantage of clustering
The main advantage of a clustered solution is automatic recovery from failure, that is, recovery without user intervention. Disadvantages of clustering are complexity and inability to recover from database corruption.
What is the advantage of clustering method
The main advantage of a clustered solution is automatic recovery from failure, that is, recovery without user intervention. Disadvantages of clustering are complexity and inability to recover from database corruption.
Why do we use clustering
Data scientists and others use clustering to gain important insights from data by observing what groups (or clusters) the data points fall into when they apply a clustering algorithm to the data.
What are two 2 differences between classification and clustering
Differences between Classification and Clustering
Classification is more complex as compared to clustering as there are many levels in the classification phase whereas only grouping is done in clustering. Classification examples are Logistic regression, Naive Bayes classifier, Support vector machines, etc.
For which method clustering is best
Density-based clustering is also a good choice if your data contains noise or your resulted cluster can be of arbitrary shapes. Moreover, these types of algorithms can deal with dataset outliers more efficiently than the other types of algorithms.
What are three advantages of cluster sampling
Cluster sampling offers the following advantages: Cluster sampling is less expensive and more quick. It is more economical to observe clusters of units in a population than randomly selected units scattered over throughout the state. Cluster Sample permits each accumulation of large samples.
What are the pros and cons of clustering algorithms
Strengths: The main advantage of hierarchical clustering is that the clusters are not assumed to be globular. In addition, it scales well to larger datasets. Weaknesses: Much like K-Means, the user must choose the number of clusters (i.e. the level of the hierarchy to “keep” after the algorithm completes).
What are the advantages of clustering data
Increased performance: Multiple machines provide greater processing power. Greater scalability: As your user base grows and report complexity increases, your resources can grow. Simplified management: Clustering simplifies the management of large or rapidly growing systems.
What are the advantages of cluster analysis
However, with cluster analysis, data scientists can assort data that share some commonality into groups. It, therefore, makes it easy to analyze and interpret massive data sets. Additionally, it helps explore and identify patterns in data sets.
Can clustering be used for classification
KMeans is a clustering algorithm which divides observations into k clusters. Since we can dictate the amount of clusters, it can be easily used in classification where we divide data into clusters which can be equal to or more than the number of classes.
What are the applications of clustering
Clustering analysis is broadly used in many applications such as market research, pattern recognition, data analysis, and image processing. Clustering can also help marketers discover distinct groups in their customer base.
Why choose clustering
As with other unsupervised learning tools, clustering can take large datasets and, without instruction, quickly organize them into something more usable. The best part is that if you're not looking to perform a massive analysis, clustering can give you fast answers about your data.
What are the advantages of clustering
Simplified management: Clustering simplifies the management of large or rapidly growing systems.Failover Support. Failover support ensures that a business intelligence system remains available for use if an application or hardware failure occurs.Load Balancing.Project Distribution and Project Failover.Work Fencing.
Why is clustering useful
Clustering is useful because it can help to find problems in the data, such as outliers. It can also be used to improve the accuracy of machine learning models by providing more information about the structure of the data.
What is the main advantage of cluster sampling
Advantages of Cluster Sampling
Since cluster sampling selects only certain groups from the entire population, the method requires fewer resources for the sampling process. Therefore, it is generally cheaper than simple random or stratified sampling as it requires fewer administrative and travel expenses.
What is the main purpose of cluster analysis
Clustering or cluster analysis is used to classify objects, characterized by the values of a set of variables, into groups. It is therefore an alternative to principal component analysis for describing the structure of a data table.
Why use clustering methods
The goal of clustering is to find natural groups, or clusters, in the data. Clustering algorithms are used to automatically find these groups. Clustering is useful because it can help to find problems in the data, such as outliers.
What are the advantages of cluster approach
The Cluster Approach aims to add value to humanitarian coordination through: Increased transparency and accountability: Greater transparency in resource allocation, co-leadership, and operational performance leads to greater accountability.
What is the main purpose of clustering
The goal of clustering is to find distinct groups or “clusters” within a data set. Using a machine language algorithm, the tool creates groups where items in a similar group will, in general, have similar characteristics to each other.
Why is clustering important in big data
Clustering big data
Clustering is a popular unsupervised method and an essential tool for Big Data Analysis. Clustering can be used either as a pre-processing step to reduce data dimensionality before running the learning algorithm, or as a statistical tool to discover useful patterns within a dataset.

