
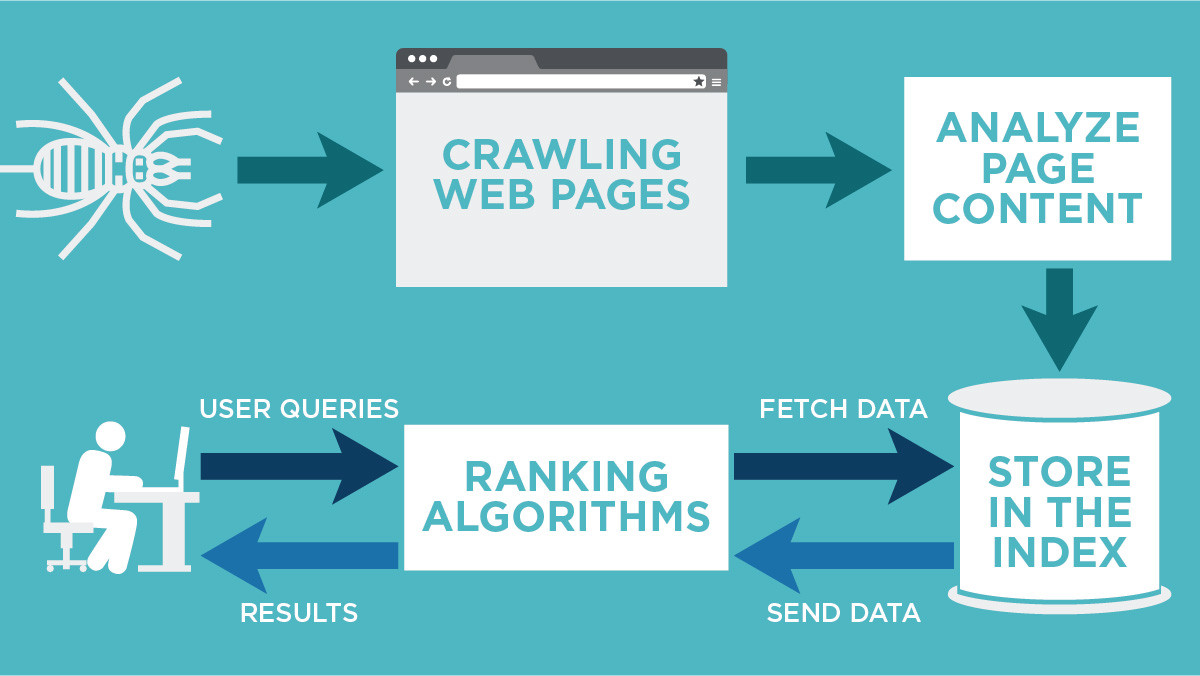
What does Google crawler see
Crawling: Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. Indexing: Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database.
What is crawler in SEO
A crawler is a program used by search engines to collect data from the internet. When a crawler visits a website, it picks over the entire website's content (i.e. the text) and stores it in a databank. It also stores all the external and internal links to the website.
Why is Google crawling important
The Googlebot crawls through web pages by following hyperlinks from one page to another, collecting information about each page along the way. This information is then used to determine the relevance and quality of the content on each page, which in turn helps Google rank web pages in its search results.
What is Googlebot crawl
Googlebot is the generic name for Google's two types of web crawlers: Googlebot Desktop: a desktop crawler that simulates a user on desktop. Googlebot Smartphone: a mobile crawler that simulates a user on a mobile device.
Does Google crawl hidden content
Well in general Google will only 'read' visible text. It will ignore hidden text, on the basis users dont see it either. So depending on how you implement the loading, if the text is still invisible when Googel 'renders' the page, Google will ignore the text.
Can web crawler be detected
Most website administrators use the User-Agent field to identify web crawlers. However, some other common methods will detect your crawler if it's: Sending too many requests: If a crawler sends too many requests to a server, it may be detected and/or blocked.
How do crawlers work
How do web crawlers work A web crawler works by discovering URLs and reviewing and categorizing web pages. Along the way, they find hyperlinks to other webpages and add them to the list of pages to crawl next. Web crawlers are smart and can determine the importance of each web page.
Why is crawling important in SEO
Crawling is crucial for SEO because it allows search engines to understand the content on your website and rank it based on relevance and quality. If your website is not crawled, it will not appear in search engine results pages (SERPs), which means you'll miss out on valuable organic traffic.
Are there benefits to crawling
One of the greatest benefits of crawling for your baby is enhancing the following fine motor skills: Lifting and turning their neck. Stretching their back muscles. Improving hand-eye coordination.
Why is crawling longer better
Crawling Improves Their Physical Capabilities
This help to improve their: Gross motor skills (the larger movements they make) Fine motor skills. Coordination.
What is the difference between crawler and bot
A web crawler, crawler or web spider, is a computer program that's used to search and automatically index website content and other information over the internet. These programs, or bots, are most commonly used to create entries for a search engine index.
Does Google crawl HTML
Google can only crawl your link if it's an <a> HTML element with an href attribute.
How do I know if Google is crawling my website
For a definitive test of whether your URL is appearing, search for the page URL on Google. The "Last crawl" date in the Page availability section shows the date when the page used to generate this information was crawled.
Does Google crawl all websites
Like all search engines, Google uses an algorithmic crawling process to determine which sites, how often, and what number of pages from each site to crawl. Google doesn't necessarily crawl all the pages it discovers, and the reasons why include the following: The page is blocked from crawling (robots.
Can you get banned for web scraping
The number one way sites detect web scrapers is by examining their IP address, thus most of web scraping without getting blocked is using a number of different IP addresses to avoid any one IP address from getting banned.
Should I block web crawlers
Protect Your Data
Bots can be used for malicious purposes such as stealing data and scraping content from websites. As a result, website owners may find it necessary to block crawlers from their website in order to protect their information and keep their site secure.
Is it legal to crawl data
Web scraping and crawling aren't illegal by themselves. After all, you could scrape or crawl your own website, without a hitch. Startups love it because it's a cheap and powerful way to gather data without the need for partnerships.
What is crawler system
A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The goal of such a bot is to learn what (almost) every webpage on the web is about, so that the information can be retrieved when it's needed.
What is crawling vs indexing in SEO
Crawling is a process which is done by search engine bots to discover publicly available web pages. Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results on search engine when a user performs a search query.
What is the difference between crawling and indexing
What is the difference between crawling and indexing Crawling is the discovery of pages and links that lead to more pages. Indexing is storing, analyzing, and organizing the content and connections between pages.
Is it OK to skip crawling
Many pediatricians will tell parents that skipping crawling is okay, and that some babies just don't crawl and instead move straight to walking.
Is it bad to skip crawling
“There is no convincing evidence that children who skip crawling are at higher risk of other sorts of developmental difficulties,” he says. As long as your baby has “the motor power, [muscle] tone, coordination, and motivation to move themselves through the environment in some way,” you don't have to worry.
Is it legal to use crawler
If you're doing web crawling for your own purposes, then it is legal as it falls under fair use doctrine. The complications start if you want to use scraped data for others, especially commercial purposes. Quoted from Wikipedia.org, eBay v. Bidder's Edge, 100 F.
Do Google crawlers run JavaScript
Google processes JavaScript web apps in three main phases: Crawling. Rendering. Indexing.
How do I trigger Google crawler
How to submit a URL for a recrawl in GSC Inspection ToolLog on to Google Search Console.Choose a property.Submit a URL from the website you want to get recrawled.Click the Request Indexing button.Regularly check the URL in the Inspection Tool.

